
Every enterprise today sits on a goldmine of data, yet most of it remains locked inside systems that were never designed to power intelligent applications. As AI adoption accelerates across industries, the gap between raw data infrastructure and AI-ready architecture has become one of the most pressing technical challenges for modern organizations.
At Prolifics, we help enterprises bridge that gap, transforming legacy data pipelines into intelligent, AI-native infrastructure that delivers real business value at speed.
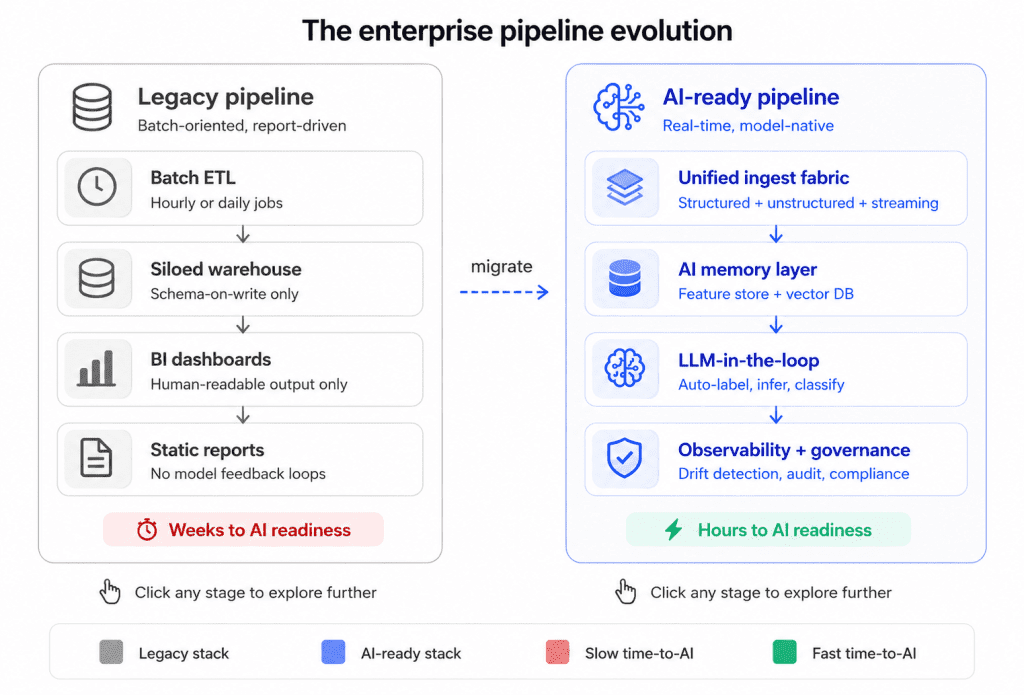
The Legacy Data Pipeline Landscape
Most enterprise data environments were built for a different era. Batch ETL workflows, siloed data warehouses, and reporting-oriented BI stacks served organizations well in a world where insight meant a weekly dashboard. Today, those same architectures create bottlenecks that directly block enterprise AI adoption at scale.
Auditing your current stack means asking hard questions about latency, flexibility, and readiness. To understand where legacy architectures fall short, consider the following:
- Batch ETL processes introduce 24-hour data delays for AI models.
- Siloed warehouses prevent unified access across enterprise data sources.
- BI stacks optimize for human reports, not machine consumption.
- Schema-on-write systems struggle with unstructured and semi-structured data.
- Tightly coupled pipelines make it costly to add new AI workloads quickly.
These architectural gaps do not just slow delivery; they fundamentally limit what AI systems can learn, infer, and act on in production environments.
Defining the AI-Ready Pipeline
An AI-ready pipeline is architecturally different from its reporting-oriented predecessor. Where traditional pipelines move data from source to destination for human analysis, AI pipelines must serve models with low latency, contextual memory, and continuous feedback loops. Understanding this distinction is essential before any enterprise begins its data to AI pipeline migration.
Core architectural principles that define an AI-ready pipeline include three foundational elements:
- Real-time feature serving keeps model inputs fresh and contextually accurate.
- Embedding pipelines convert raw data into dense, semantically rich vector representations.
- Model-in-the-loop design allows AI outputs to influence downstream pipeline decisions dynamically.
These principles shift the pipeline from a passive data mover to an active participant in intelligent workflows, creating the foundation for sustainable and scalable AI acceleration.
AI Acceleration
1. Unified Ingest for AI Workloads
One of the most common bottlenecks in enterprise AI pipeline implementation is fragmented data ingestion. When structured transactional records, unstructured documents, and real-time event streams flow through separate pipelines, AI models face an incomplete and inconsistent view of the business. Building a unified ingest fabric resolves this by consolidating all data types into a single ingestion layer that any model can access with minimal latency.
Consolidating ingest at the architectural level produces outcomes that significantly accelerate AI adoption across the enterprise:
- Unified schemas reduce data transformation overhead for every new AI model.
- Real-time event ingestion enables models to respond to live business signals.
- Streaming and batch ingestion coexist without separate engineering teams managing each.
- Unstructured content including PDFs, emails, and logs enters the same pipeline as structured records.
- Any enterprise data source becomes accessible to AI workloads without custom connectors.
This approach converts your data infrastructure into an AI-accessible fabric, removing the last-mile friction that often delays time-to-production for new models.
2. Feature Stores and Vector Databases
As enterprises scale up their AI initiatives, they quickly discover that raw data alone is insufficient for model performance. AI models require pre-computed, consistently formatted inputs delivered at millisecond speeds. This is where the AI memory layer becomes critical, consisting of feature stores for structured model inputs and vector databases for semantic retrieval.
| Dimension | Feature Store | Vector Database |
| Primary purpose | Manage, store, and serve pre-computed ML features for predictive models. | Store and retrieve high-dimensional vector embeddings for semantic search and RAG. |
| Data format | Structured, tabular features; numerical values, categorical encodings, aggregations. | Dense float vectors (embeddings) representing the semantic meaning of text, images, or records. |
| Query type | Exact key-value lookup by entity ID (e.g. user ID, product ID) with millisecond latency. | Approximate nearest neighbour (ANN) search to find semantically similar items by vector proximity. |
| Core problem solved | Prevents training-serving skew; ensures models see the same features at inference as at training time. | Enables LLMs to retrieve relevant context from enterprise knowledge bases before generating responses. |
| Use case in AI pipeline | Real-time personalization, fraud detection, churn prediction; any model that needs structured signals. | Retrieval-augmented generation (RAG), semantic search, document Q&A, and recommendation systems. |
| Reusability | Features are shared across multiple models; one computation serves many downstream workloads. | Embedding registries store indexed vectors once and serve them across multiple LLM-powered applications. |
| Typical tools | Feast, Tecton, Hopsworks, AWS SageMaker Feature Store. | Pinecone, Weaviate, Milvus, pgvector, Qdrant, Chroma. |
| Best for | Predictive ML models that rely on structured, frequently updated business signals. | Generative AI applications that need grounding in proprietary enterprise knowledge and context. |
Together, these two components form a robust AI memory layer. Feature stores provide consistency and speed for predictive models, while embedding registries and vector search infrastructure power generative AI applications. Building this layer early reduces the cost and complexity of every AI workload that follows.
LLM-in-the-Loop Pipeline Acceleration
One of the most transformative shifts in modern AI pipeline architecture is using large language models not just as endpoints but as active participants in the pipeline itself. Embedding generative AI directly into data preparation stages compresses timelines that traditionally took weeks into hours, dramatically reducing time-to-AI for enterprise data teams.
LLMs bring intelligence to tasks that previously required extensive manual engineering:
- Auto-labeling assigns semantic tags to unlabeled datasets without human intervention.
- Schema inference generates structured metadata from raw, unstructured data sources.
- Semantic classification categorizes records based on meaning rather than rigid rules.
- Code generation writes transformation logic, reducing data engineering cycle time significantly.
- Anomaly narration produces human-readable explanations for unusual data patterns automatically.
Now see how embedding LLMs into your pipeline compresses weeks of manual data preparation into hours; click each stage to explore the time savings.
When enterprises embed LLMs into their pipeline operations, they stop treating AI as the final step in a long process and start treating it as an accelerant throughout the entire data lifecycle.

Governance and Scale
Observability, Quality, and Model Monitoring
Why It Matters?
AI pipelines without observability are production liabilities. Unlike traditional software where bugs produce deterministic errors, AI pipelines fail silently. A model can continue to produce outputs while gradually drifting away from accuracy, and without the right monitoring infrastructure, that drift goes undetected until it causes real business harm.
Maintaining trust in AI outputs at enterprise scale demands closed-loop feedback mechanisms, not just point-in-time validation. Organizations operating across global footprints need observability frameworks that cover the full pipeline lifecycle, from ingest quality to model output reliability.
Effective observability covers three critical dimensions:
- Data drift detection flags when incoming data distributions shift unexpectedly over time.
- End-to-end data lineage traces every record from its source to its model output.
- SLA tracking ensures AI pipelines meet latency and freshness commitments reliably.
Without this layer, responsible AI deployment remains aspirational rather than operational.
Enterprise Governance and Responsible AI
Governance cannot be a retrofitted concern. When privacy handling, bias mitigation, and regulatory compliance get added after deployment, they create fragile controls that break under scale. For enterprises with global operations, embedding governance at the ingest layer is the only architecture that holds.
Prolifics designs AI pipeline governance frameworks that satisfy regulatory requirements across multiple jurisdictions simultaneously:
- PII detection and masking runs at ingest, not at reporting, reducing downstream exposure risk.
- Bias evaluation checkpoints run at feature creation and model training stages consistently.
- GDPR and DPDP compliance controls govern data residency, consent, and deletion workflows.
- SOC 2 audit trails capture every pipeline action with tamper-evident logging automatically.
- Role-based access controls restrict sensitive data exposure to authorized model and team usage.
Treating governance as a first-class architectural component rather than a compliance overlay ensures that AI systems earn and maintain the trust of regulators, customers, and the enterprise itself.
Conclusion
The journey from data pipelines to AI pipelines is not a lift-and-shift migration. It demands a deliberate architectural evolution, one that replaces batch-oriented, report-driven infrastructure with real-time, model-ready systems built for continuous learning and generative intelligence. The enterprises that move fastest are those that unify their ingest layer, build a scalable AI memory layer through feature stores and vector databases, accelerate data preparation with LLM-in-the-loop processing, and embed governance from day one.
Prolifics brings the engineering depth, enterprise experience, and end-to-end AI pipeline expertise to help organizations achieve this transformation at speed. Whether you are at the audit stage or ready to scale production AI workloads, our teams are equipped to accelerate every step of the journey.


