
Enterprise Document Intelligence starts with a real problem. A global enterprise once struggled to extract insights from thousands of contracts, invoices, and reports stored across disconnected systems. Critical decisions were delayed, and opportunities were missed because valuable data remained locked in unstructured formats. This challenge is becoming more common as businesses scale their digital operations.
AI agents can’t reliably read your documents.
Not because they aren’t intelligent. Not because the reasoning models are weak. The bottleneck is something more fundamental: the document processing layer beneath the agent is broken. And until you fix it, every agentic workflow you build is operating on a cracked foundation.
At Prolifics, we work with enterprises across banking, healthcare, insurance, and financial services; industries where document-heavy workflows are not edge cases, they are the core business. This blog breaks down why frontier AI agents fail at reading enterprise documents, what the research says, and how modern Document Intelligence pipelines are finally closing that gap.
Why Can’t AI Agents Read Enterprise Documents
Enterprise documents are often complex, unstructured, and inconsistent in format. AI models struggle to interpret context, layout, and relationships within such data. This limits their ability to deliver reliable outputs in enterprise environments. Without proper structuring, even advanced models fail to extract meaningful insights.
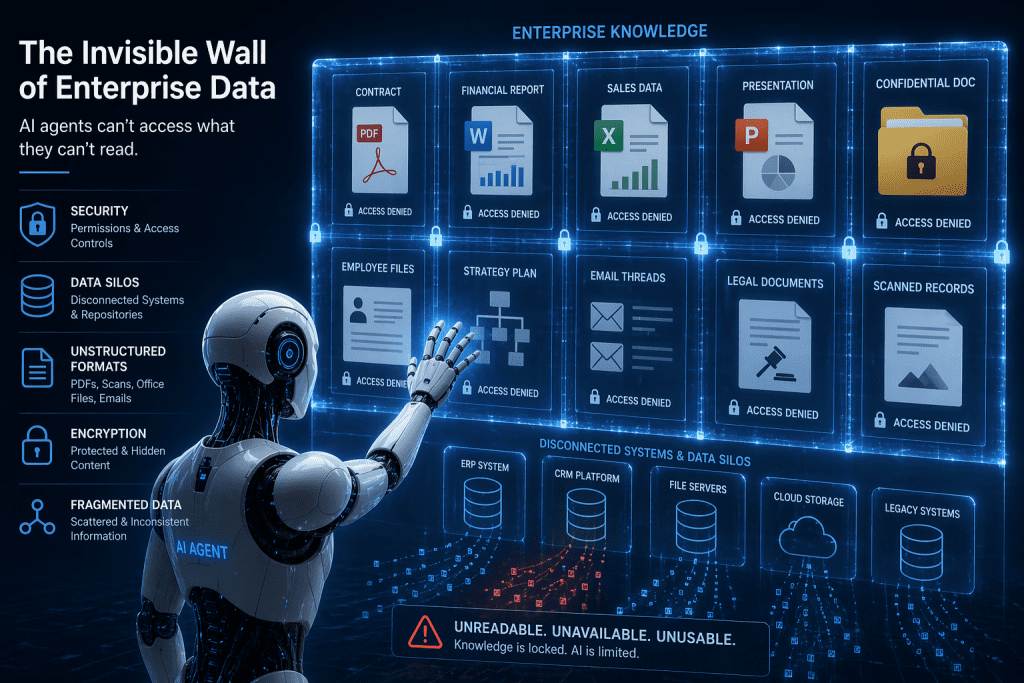
The following challenges explain why AI agents struggle with enterprise documents.
- Documents contain mixed formats, layouts, and inconsistent structural hierarchies across systems.
- Lack of contextual metadata limits understanding of relationships within document content.
- Scanned PDFs reduce text clarity, affecting accurate data extraction and interpretation.
- Complex tables and images disrupt standard parsing methods used by AI systems.
- Domain-specific language requires specialized models for accurate comprehension and extraction.
Unstructured PDF Data Extraction for AI Agents
In today’s digital economy, businesses generate massive volumes of unstructured data daily. Extracting insights from PDFs, contracts, and reports is essential for automation and decision-making. Unstructured Data Extraction AI plays a critical role in enabling AI-driven enterprises to operate efficiently.
The following capabilities highlight the importance of modern extraction techniques.
- Extracts structured data from unstructured PDFs using advanced machine learning techniques.
- Enables real-time decision-making through accurate and contextual data interpretation workflows.
- Supports compliance by capturing critical information from regulatory and financial documents.
- Improves operational efficiency by reducing manual document handling and processing delays.
- Enhances Generative AI Document Understanding for better enterprise-level automation outcomes.
Building a Strong Document Foundation for Agentic AI Workflows
A strong document foundation is essential for enabling Agentic AI Enterprise Workflows. Without structured and contextualized data, AI agents cannot perform reliably. Organizations must invest in systems that standardize, enrich, and govern document data effectively. This includes integrating metadata, improving data quality, and enabling real-time access.
Modern enterprises require scalable architectures that support continuous learning and adaptation. By aligning document intelligence with AI workflows, businesses can unlock new levels of automation and insight. This foundation becomes the backbone of AI Document Automation Enterprise initiatives.
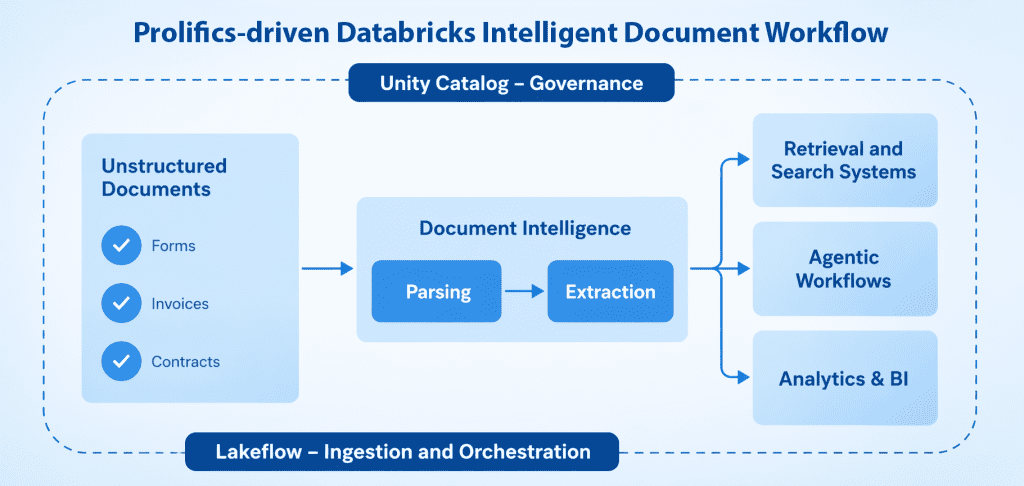
How Prolifics Helps
The following capabilities demonstrate how we enables enterprise document intelligence success.
- Designs scalable architectures for Enterprise Document Intelligence across complex enterprise ecosystems.
- Implements Intelligent Document Processing IDP solutions tailored to industry-specific requirements.
- Integrates Databricks Document Intelligence for unified data processing and advanced analytics.
- Enables secure and compliant AI workflows with robust governance and data controls.
- Accelerates AI Agents Document Processing through optimized pipelines and automation frameworks.
Agentic AI Workflow Document Foundation
Agentic AI Enterprise Workflows rely heavily on accurate, structured, and accessible document data. A strong foundation ensures consistency, scalability, and reliability in automated decision-making processes. It also supports continuous improvement through feedback-driven learning mechanisms.
The following elements are critical for building a reliable document foundation.
- Standardized data models ensure consistency across enterprise document processing workflows.
- Metadata enrichment improves context awareness for AI-driven document understanding systems.
- Real-time data pipelines enable faster insights and decision-making capabilities.
- Governance frameworks ensure compliance, security, and data integrity across operations.
What Is Intelligent Document Processing (IDP)
Intelligent Document Processing (IDP) is the use of AI and machine learning to automatically extract, classify, and structure information from unstructured documents PDFs, scanned forms, invoices, contracts, medical records, and more.
For the past decade, IDP was treated as a back-office automation problem. You’d bolt on an OCR tool, wire in an extraction API, and call it done. It was narrow, brittle, and constantly breaking when document formats changed.
In the agentic AI era, IDP has a fundamentally different role. It is no longer a back-office utility. It is the critical foundation layer that determines whether your AI agents make decisions you can trust; or quietly make expensive mistakes at scale.
IDP is a key enabler of Enterprise Document Intelligence and AI-driven transformation:
- Automates extraction of structured data from complex and unstructured enterprise documents.
- Uses machine learning models to improve accuracy and adaptability over time.
- Integrates with enterprise systems to enable seamless workflow automation processes.
- Enhances AI Document Automation Enterprise initiatives with scalable and intelligent capabilities.
Databricks Document Intelligence for the Enterprise
Databricks Document Intelligence provides a unified platform for processing and analyzing large volumes of document data. It combines data engineering, machine learning, and analytics to enable scalable solutions. Organizations can leverage this platform to build robust AI-driven document workflows.
By integrating Databricks Document Intelligence with enterprise systems, businesses gain improved visibility and control over their data. It supports advanced analytics and enhances Generative AI Document Understanding capabilities.
- Unified data platform supports scalable document processing across enterprise environments.
- Advanced analytics enable deeper insights from structured and unstructured document data.
- Integration with AI models enhances accuracy and contextual understanding of documents.
- Supports real-time processing for faster and more efficient decision-making workflows.
- Enables seamless collaboration across teams through centralized data and analytics systems.
How Prolifics Helps Enterprises Build Document-Ready AI Agents
At Prolifics, our approach to enterprise document intelligence combines three capabilities:
- Advisory and architecture: We assess your current document processing landscape, identify accuracy gaps, and design the right pipeline architecture for your document types, volumes, and governance requirements.
- Implementation on Databricks: We build production-grade Document Intelligence pipelines using Databricks AI Functions, integrated with your existing data platform, orchestration layer, and Unity Catalog governance.
- Agentic workflow integration: We connect your document intelligence layer to the broader agentic workflows your teams are building, ensuring that agents receive clean, structured, layout-aware data rather than raw scans.

The goal is not just better document extraction. It is an enterprise-wide Document Intelligence capability; a reusable foundation that every team can build on, governed end to end, and scalable from day one.
AI Agent Document Processing Accuracy
Accuracy is the foundation of successful AI Agents Document Processing. Without reliable outputs, automation can introduce risks instead of delivering value. Enterprise documents often contain complex structures, domain-specific language, and contextual dependencies that challenge traditional AI models.
To achieve high accuracy, organizations must focus on data quality, model training, and continuous validation. This includes using domain-specific models, refining extraction techniques, and implementing feedback loops. Generative AI Document Understanding further enhances accuracy by enabling contextual reasoning rather than simple pattern recognition.
Prolifics emphasize a structured approach to improving accuracy by combining Intelligent Document Processing (IDP) with advanced AI techniques. This ensures that extracted data is not only correct but also meaningful and actionable. By integrating governance and validation frameworks, businesses can trust their AI-driven insights and scale confidently.
How to Fix AI Document Extraction Errors
AI document extraction errors often arise from poor data quality, inconsistent formats, and lack of contextual understanding. Addressing these issues requires a combination of advanced tools and structured methodologies, as highlighted in Databricks approaches.
The following steps outline a robust architecture for AI Document Automation Enterprise solutions.
Step 1: Parse Once, Reuse Everywhere
The first step involves transforming raw documents into structured, layout-aware text. This process preserves spatial relationships such as table structures, column alignment, and hierarchical elements like headings and data fields. A well-parsed document becomes a reusable asset within the data pipeline, often referred to as a silver layer. This enables multiple downstream operations such as classification and extraction without reprocessing the original document.
- Converts raw PDFs and scans into structured, layout-aware text representations.
- Preserves document structure including tables, columns, headings, and relationships accurately.
- Creates reusable data assets for downstream AI Agents Document Processing workflows.
- Reduces redundant processing and improves efficiency across enterprise document pipelines.
- Enhances Generative AI Document Understanding with context-rich structured document outputs.
Step 2: Classify Documents Accurately
Once documents are parsed, they must be accurately classified to ensure correct routing within the processing pipeline. Each document type requires a specific extraction logic, and errors at this stage can propagate downstream. Accurate classification is essential for maintaining efficiency and reliability in Intelligent Document Processing (IDP) systems.
- Identifies document types such as invoices, contracts, medical records, and filings.
- Routes documents to appropriate extraction models based on classification results.
- Minimizes downstream errors caused by incorrect document categorization workflows.
- Improves scalability of AI Agents Document Processing across enterprise use cases.
- Reduces manual intervention by enabling automated and intelligent document routing systems.
Step 3: Extract Structured Insights
The final step focuses on extracting meaningful and structured data from classified documents. This includes identifying key entities and domain-specific information required for business operations. The effectiveness of this step depends on the quality of both parsing and classification stages.
- Extracts key entities such as invoice numbers, dates, clauses, and amounts.
- Applies domain-specific logic for accurate Unstructured Data Extraction AI workflows.
- Improves data accuracy through context-aware extraction powered by advanced AI models.
- Enables seamless integration with downstream enterprise systems and analytics platforms.
- Supports AI Document Automation Enterprise initiatives with scalable and reliable extraction processes.
Enterprise benchmarks across invoices, contracts, medical records, and financial filings show that specialized pipelines consistently achieve higher accuracy. These pipelines also operate at significantly lower cost compared to general-purpose vision-language model approaches that reprocess entire documents repeatedly.
By adopting this structured and scalable architecture, organizations can significantly enhance AI Agent Document Processing accuracy while reducing operational complexity. We helps enterprises implement these best practices using Databricks Document Intelligence and Intelligent Document Processing (IDP), ensuring reliable, efficient, and enterprise-ready document intelligence solutions.
Frontier AI Agents Document Benchmark
Evaluating AI performance requires standardized benchmarks that measure accuracy, context understanding, and scalability. Frontier AI agents are tested against real-world document scenarios to assess their effectiveness.
- Benchmark models using diverse document types including PDFs, images, and tables.
- Measure contextual understanding and accuracy across complex enterprise document scenarios.
- Evaluate scalability to handle large volumes of enterprise document processing workloads.
- Compare performance across different AI models to identify optimal solutions.
Conclusion
Enterprise documents hold valuable insights, but without the right approach, they remain underutilized. Enterprise Document Intelligence, Intelligent Document Processing (IDP), and Databricks Document Intelligence are transforming how businesses extract and use this data.
We helps organizations build strong foundations for Agentic AI Enterprise Workflows by enabling accurate, scalable, and secure AI Agents Document Processing. Our expertise ensures that unstructured data becomes a strategic asset, driving better decisions and measurable business outcomes.


