
Modern organizations generate large amounts of data from applications, customers, operations, and digital platforms. To convert this data into business value, companies need a reliable analytics foundation. That foundation usually includes a data lake, a data warehouse, or a mix of both.
Choosing between a data lake vs data warehouse is not only a technical decision. It directly impacts reporting speed, business intelligence accuracy, and how easily teams can scale analytics.
What is Data Lake?
A data lake is a centralized storage system that holds large volumes of raw data in its original format. This data can be structured (tables), semi-structured (JSON, logs), or unstructured (images, audio, text). Data lakes are designed for flexibility and scale, making them useful for big data analytics architecture and advanced analytics workloads.
Data lakes are commonly built on cloud storage or distributed storage systems and are optimized for storing massive datasets at low cost.
What is Data Warehouse?
A data warehouse is a centralized system designed to store structured, cleaned, and organized data for reporting and analytics. It collects data from multiple sources, transforms it into consistent formats, and stores it using predefined schemas.
Data warehouses focus on fast querying, consistent metrics, and trusted reporting, which is why they are widely used for business intelligence and operational dashboards.
Why Both Matter for Analytics?
Both systems play important roles in modern data analytics platforms. A data lake supports broad data storage, exploration, and machine learning. A data warehouse supports structured analytics, KPI tracking, and stable reporting.
In short, the data lake enables flexibility, while the data warehouse ensures consistency. Many organizations use both together to balance speed, cost, governance, and business needs.
Architecture Overview of Data Lake and Data Warehouse
When comparing data lake vs data warehouse architecture, the biggest difference is how data flows and how structured it becomes. It depends on your needs. Data lakes are best for big data and machine learning while Data warehouses are best for reports and dashboards. Let us explore both architectures one by one.
Standard Data Lake Architecture
The diagram and steps explain how a data lake collects, stores, processes, and serves data for analytics:
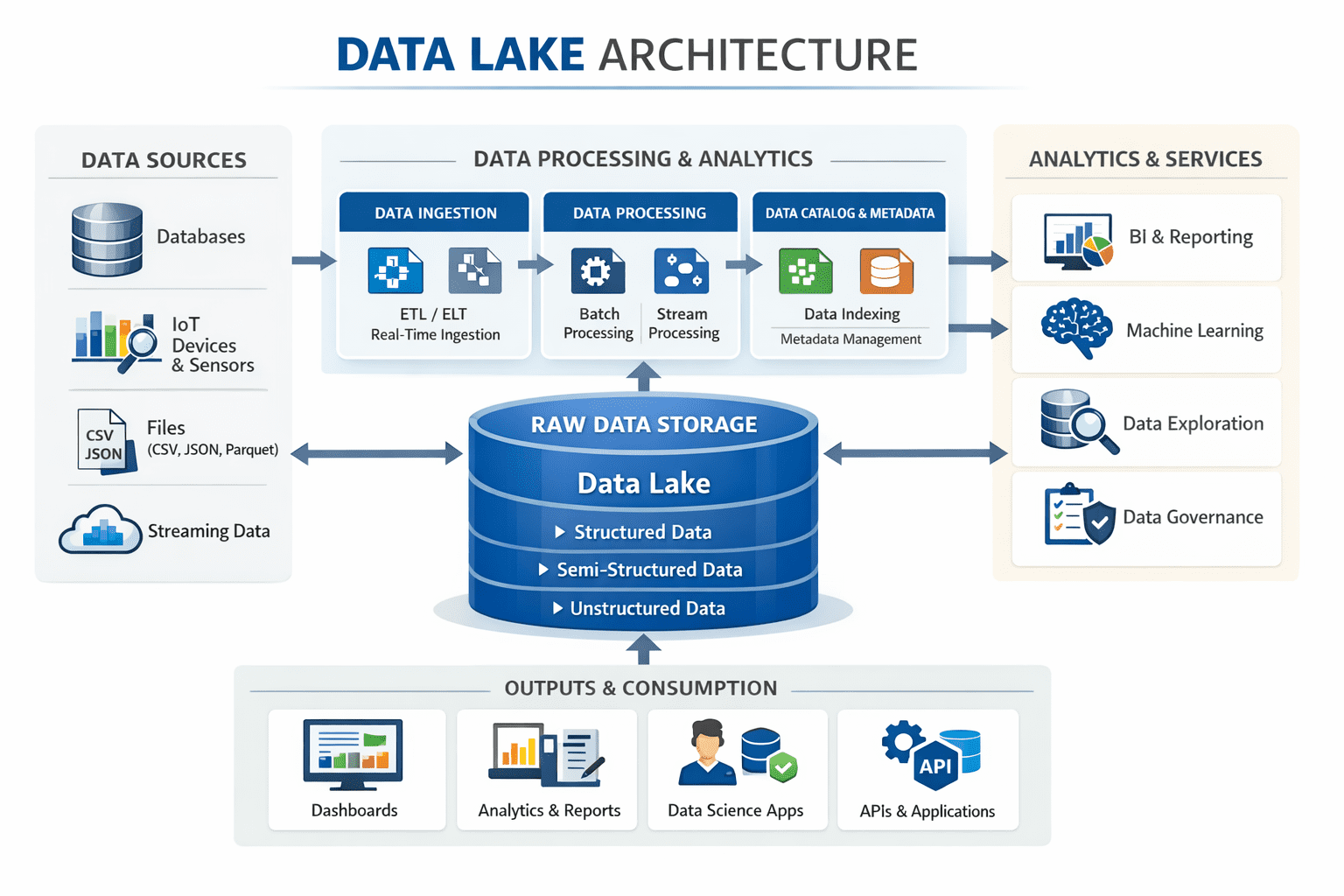
Step 1: Data is ingested from apps, IOT, logs, APIs, and databases.
Step 2: Storage layer keeps raw data in original format.
Step 3: Processing layer transforms data using ETL or ELT.
Step 4: The Query layer supports analytics and data exploration.
Step 5: Curated zone stores business-ready datasets when required.
Standard Data Warehouse Architecture
To understand the data warehouse architecture, the following steps explain how data is processed for reporting:
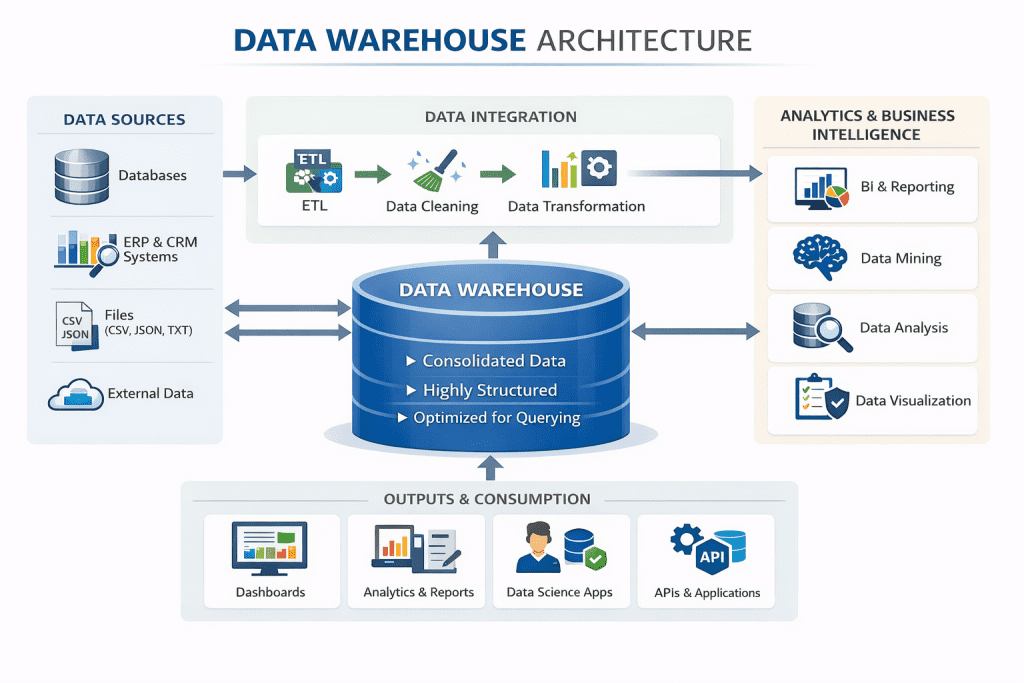
Step 1: Source systems send data into ETL pipelines.
Step 2: Data is cleaned and transformed before loading into a warehouse.
Step 3: The central warehouse stores standardized and structured tables.
Step 4: BI tools use curated datasets for reporting and dashboards.
In many analytics environments, the data lake acts as a scalable storage foundation, while the data warehouse acts as the trusted analytics layer.
Difference Between Data Lake and Data Warehouse
Below the table compares the most common data warehouse and data lake differences for analytics teams:
| Data lake | Data Warehouse |
| A data lake stores structured, semi-structured, and unstructured data. | A data warehouse mainly stores structured and cleaned data. |
| A data lake keeps data in its raw, original format. | A data warehouse stored data in a transformed and standardized format. |
| This follows a schema-on-read approach, where schema is applied when data is used. | A data warehouse follows a schema-on-write approach, where schema is defined before data is stored. |
| It is best for exploration, AI/ML, data science, and big data processing. | It is best for BI reporting, dashboards, and KPI monitoring. |
| Performance in a data lake depends on the processing layer and query engine used. | Data warehouses are optimized for high-performance analytics queries. |
| Governance in a data lake can become complex without strong controls and policies. | A data warehouse supports strong governance and standardized reporting. |
Data Lake vs Data Warehouse Use Cases
Data lake vs data warehouse use cases depend on how you store and use data. Data lakes support raw and large-scale data, while data warehouses support clean data for BI reporting. Many modern platforms use both to cover all analytics needs.
Use Cases of Data Lake
A data lake is best when you need flexible storage for large and diverse data. It is useful when data formats keep changing, and you want to scale analytics easily.
- Store raw data from multiple sources in one place.
- Support machine learning and AI model training.
- Analyze logs, IoT data, and streaming data.
- Enable exploratory analytics and ad-hoc analysis.
- Keep historical data for future analysis needs.
Use Cases of Data Warehouse
A data warehouse is best when you need clean, trusted data for reporting. It keeps data consistent across teams, so everyone sees the same numbers. It also delivers fast query performance, which is important for dashboards and KPIs.
- Build dashboards for business teams and leadership.
- Track KPIs and performance metrics consistently.
- Support structured reporting and trend analysis.
- Combine data from systems into standardized tables.
- Provide fast SQL queries for business intelligence reports.
How AI Analytics Supports Both Data Lakes and Data Warehouses?
AI and LLM-driven analytics require data platforms that can handle diverse and unstructured data at scale. Real-time analytics is now a standard need, so organizations must ensure low-latency access to data for faster decisions. As data environments grow, strong metadata, cataloging, and semantic layers become critical to build trust and governance. To stay flexible for long term, open formats and APIs are essential for interoperability and future growth.
AI Analytics in Data Lake
The following are the key infrastructure changes organizations need to support AI and real-time analytics in data lake:
- It finds useful patterns in raw data like logs, text, images, and IoT data.
- It supports machine learning training using large datasets.
- It helps automate data classification and tagging for faster discovery.
- It improves data quality checks at a scale.
AI Analytics in Data Warehouse
Here are the key data warehouse infrastructure changes needed to support AI and real-time analytics:
- It improves forecasting, trend analysis, and KPI prediction using clean data.
- It automates reporting insights like anomalies, risks, and performance drops.
- It enables smarter dashboards using natural language questions.
- It helps business teams make faster decisions from structured data.
Conclusion
Data lakes and data warehouses are both important for analytics, but they solve different problems. A data lake helps you store and work with large, mixed data, which is useful for AI and advanced analytics. A data warehouse helps you keep data clean and consistent, so reporting and dashboards stay accurate. In real business environments, many companies use both together to get the best results. As AI and real-time insights become more common, the real focus should be on building scalable systems with strong governance and flexible, open architecture.
