Artificial Intelligence is reshaping how enterprises build, modernize, and manage software. Yet many organizations continue to face challenges with legacy systems, fragmented development environments, governance requirements, and increasing pressure to deliver innovation faster.
IBM Bob is an AI-first enterprise development platform designed to support the entire Software Development Lifecycle (SDLC), from planning and code generation to testing, deployment, modernization, and governance. When combined with Prolifics’ deep expertise in enterprise transformation, organizations gain a powerful framework to accelerate modernization initiatives while maintaining security, compliance, and operational excellence.
Why IBM Bob + Prolifics?
Accelerate legacy application modernization and cloud transformation
Improve developer productivity with AI-assisted SDLC automation
Strengthen governance, security, and compliance across development workflows
Integrate AI into DevSecOps, CI/CD, and enterprise engineering practices
Reduce technical debt and streamline software delivery
Scale AI adoption responsibly across hybrid and multi-cloud environments
Modernize mainframe, IBM i, COBOL, and legacy enterprise systems
Enable faster innovation with enterprise-ready AI solutions
Whether you’re modernizing mission-critical applications, optimizing software delivery, or building an AI-driven development strategy, Prolifics helps you unlock the full value of IBM Bob.
Discover how IBM Bob and Prolifics help enterprises move from experimentation to production-ready AI-powered software engineering.
When a senior developer retired after twenty-five years, critical business processes began slowing down because no one fully understood the rules embedded within legacy systems. What first looked like a technology issue quickly became a business continuity risk. This happens across enterprises every day, where valuable operational knowledge lives inside aging applications, undocumented workflows, spreadsheets, emails, and employee experience. As organizations move toward modernization, automation, and AI, uncovering hidden business logic becomes essential for reducing risk, preserving institutional knowledge, improving decisions, and building long-term competitive advantages with AI.
At Prolifics, we help organizations identify, extract, and transform hidden business logic into actionable intelligence that supports modernization, operational efficiency, and sustainable growth.
The Enterprise Blindspot: What Is Hidden Business Logic in Enterprise AI?
Hidden business logic in enterprise AI refers to the undocumented rules, decision trees, and operational knowledge embedded in legacy systems, employee expertise, and informal workflows. It is the invisible layer that drives real business outcomes and the missing context that causes AI models to underperform when left unaddressed.
Hidden business logic consists of the rules, decisions, workflows, and operational knowledge that drive business processes but remain undocumented or difficult to access. Over time, these business rules become deeply embedded within enterprise systems, employee expertise, and daily operations. As a result, organizations often struggle to fully understand, manage, or modernize the processes that keep their business running.
This challenge sits at the center of hidden business logic in enterprise AI. Without visibility into critical operational knowledge, businesses struggle to modernize systems, scale operations, reduce risk, and maintain consistency across teams.
The following challenges commonly prevent organizations from accessing and leveraging hidden business logic effectively:
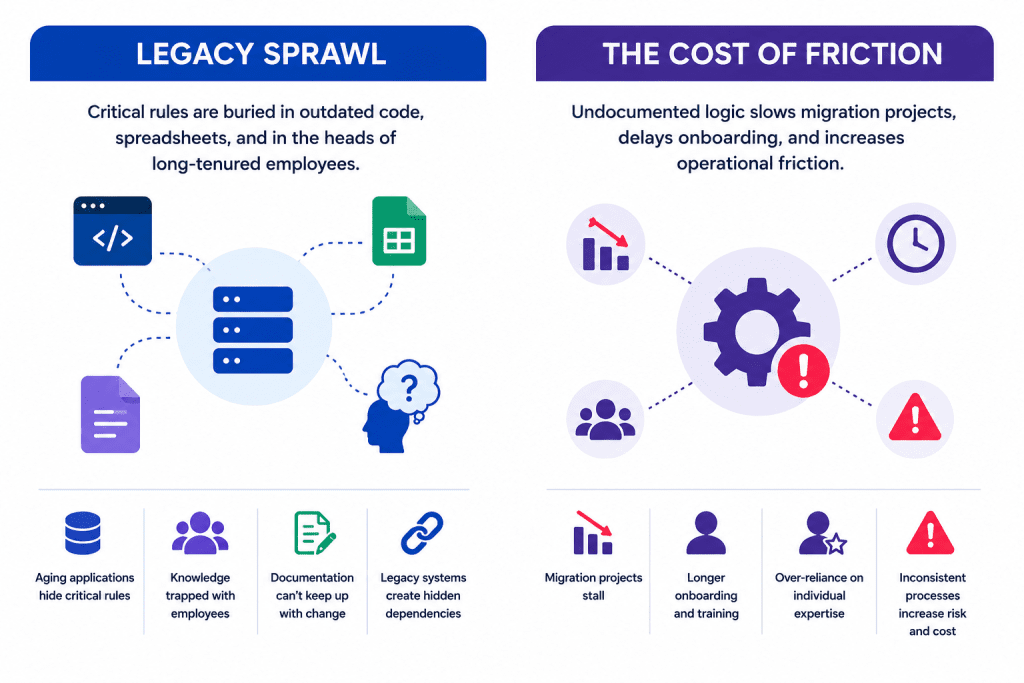
Legacy Sprawl
The Cost of Friction
i. Legacy Sprawl: Why Critical Rules Sit Buried in Outdated Code and Employee Heads
Many enterprises operate hundreds of interconnected applications developed over decades. Business rules often exist inside custom code, obsolete systems, spreadsheets, and informal processes maintained by long-tenured employees. As systems evolve, documentation rarely keeps pace, creating significant knowledge gaps.
This fragmentation makes modernization initiatives increasingly difficult. Teams cannot confidently update systems when they do not fully understand the logic driving business outcomes. The result is increased risk, higher costs, slower innovation, and reduced readiness for AI adoption.
Common consequences of legacy sprawl include:
Critical business rules remain hidden inside aging applications.
Employee departures create significant knowledge retention and business continuity risks.
Documentation fails to reflect evolving business process requirements.
Legacy systems obscure dependencies across enterprise operations.
Teams struggle to identify the impact of changes across interconnected systems.
ii. The Cost of Friction: How Undocumented Logic Slows Down Software Migration and Onboarding
Organizations frequently invest millions in digital transformation and modernization initiatives. However, undocumented business logic often becomes a major obstacle during migration projects. Teams spend significant time reverse-engineering workflows before modernization efforts can begin.
New employees face similar challenges. Without clear documentation, onboarding requires extensive tribal knowledge transfer, reducing productivity and increasing dependency on experienced personnel.
The following challenges create operational friction across the enterprise:
Migration projects stall while teams decode undocumented workflows.
New employees require extended onboarding and process training.
Business decisions depend heavily on individual employee expertise.
Process inconsistencies increase operational costs and compliance risks.
Modernization timelines expand due to uncertainty around business rules.
Why Hidden Business Logic Matters More in the Age of AI
The rise of enterprise AI has increased the importance of understanding business logic. AI systems are only as effective as the knowledge and processes they are trained to support. When critical business rules remain hidden, organizations risk building AI solutions on incomplete or inaccurate information.
AI initiatives require a clear understanding of how decisions are made, how workflows operate, and how exceptions are handled. Without this foundation, automation efforts may introduce errors, compliance issues, and operational inefficiencies.
Organizations that successfully uncover hidden business logic gain several advantages:
Better decision-making through access to institutional knowledge.
Reduced dependency on individual employees.
How AI Helps Uncover Hidden Business Logic
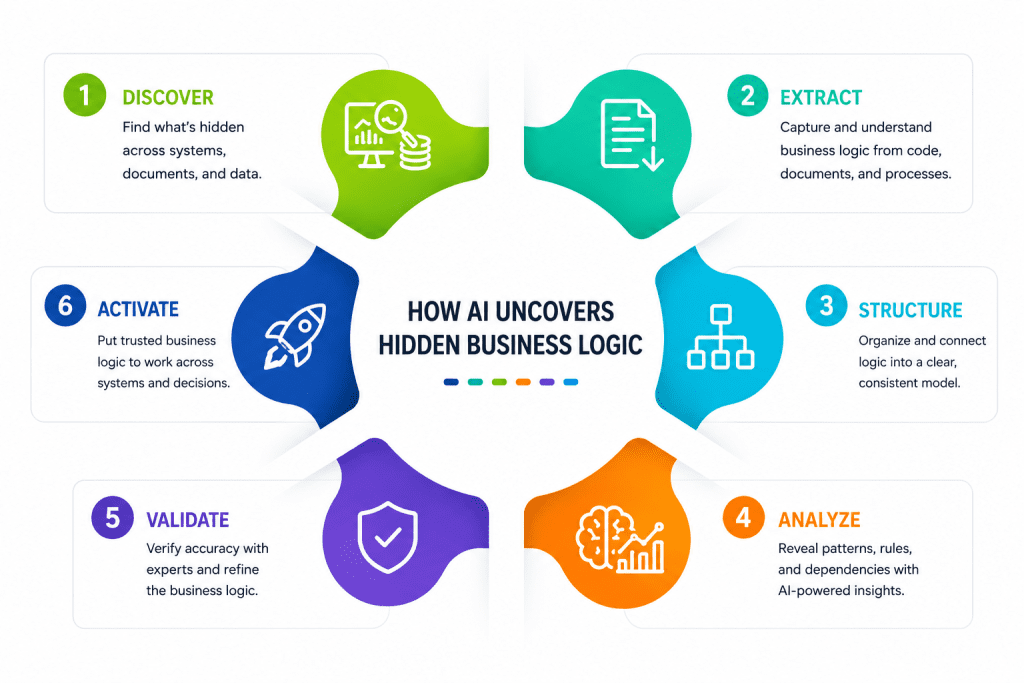
AI uncovers tacit knowledge in business processes by analyzing legacy source code, unstructured documents, emails, system logs, and expert interviews at scale. Unlike manual discovery, AI identifies patterns, decision rules, and workflow logic across thousands of data sources simultaneously, turning invisible institutional knowledge into structured, actionable intelligence.
Traditional approaches to documenting business processes often rely on interviews, manual reviews, and lengthy discovery projects. While valuable, these methods can be time-consuming and incomplete.
Modern AI technologies can accelerate discovery by analyzing large volumes of structured and unstructured data across the enterprise. AI can identify patterns, relationships, workflows, and decision rules that would otherwise remain hidden.
i. Analyzing Legacy Applications and Source Code
AI-powered tools can examine legacy applications, source code repositories, and system configurations to identify embedded business rules. This enables organizations to understand how systems operate without relying solely on historical documentation.
Benefits include:
Faster application assessment.
Improved migration planning.
Reduced modernization risk.
Better visibility into system dependencies.
ii. Mining Documentation, Emails, and Knowledge Repositories
Important business knowledge often exists outside formal systems. AI can analyze documents, emails, support tickets, process manuals, and collaboration platforms to uncover operational insights and decision-making patterns.
This helps organizations:
Capturing workflows that teams follow but rarely document clearly.
Preserving institutional knowledge before employees leave or roles change.
Identifying process variations that create confusion across business teams.
Improving knowledge access so teams find answers faster.
iii. Extracting Knowledge from Subject Matter Experts
Experienced employees often possess valuable operational knowledge that has never been formally documented. AI-assisted interviews, knowledge capture platforms, and conversational tools can help organizations preserve expertise before it is lost.
This approach helps organizations protect important expertise in practical ways:
Keeping critical knowledge available before experienced employees move on.
Helping new employees learn processes with less confusion.
Reducing business continuity risks tied to individual expertise.
Improving process documentation with clearer, more reliable details.
Transforming Hidden Business Logic into Actionable Intelligence
Discovering hidden business logic is only the first step. Organizations must also convert that knowledge into usable assets that support modernization and innovation.
Once extracted, business logic can be organized into centralized repositories, knowledge graphs, process maps, and governance frameworks that make information accessible across the enterprise.
Key outcomes include the following:
Creating consistent business rules teams can understand and apply.
Making processes easier to see, review, and improve.
Helping teams work together with shared operational contexts.
Connecting business priorities with technology decisions more clearly.
Building stronger foundations for future AI and automation initiatives.
Business Benefits of Uncovering Hidden Business Logic
Organizations that successfully identify and operationalize hidden business logic can realize significant business value.
i. Strengthening Business Continuity
When critical knowledge is documented and accessible, organizations become less dependent on individual employees. This reduces operational disruptions caused by retirements, turnover, or organizational changes.
ii. Accelerating Digital Transformation
Understanding existing business rules enables teams to modernize systems with greater confidence. Projects move faster because stakeholders have a clear view of current-state processes and dependencies.
iii. Improving Operational Efficiency
Documented workflows reduce duplication, eliminate unnecessary manual effort, and improve consistency across operations. Teams spend less time searching for information and more time delivering value.
iv. Enhancing Compliance and Risk Management
Clear visibility into business rules helps organizations demonstrate compliance, improve governance, and reduce operational risk. AI can also help identify inconsistencies and gaps that may create regulatory exposure.
v. Enabling Smarter AI Initiatives
Organizations with well-documented business logic provide AI systems with higher-quality context and decision frameworks. This improves the effectiveness of automation, analytics, and intelligent decision-making solutions.
Building a Competitive Advantage with AI
The organizations that gain the greatest value from AI are not necessarily those with the most advanced technology. They are the ones that understand their business processes, operational knowledge, and decision-making frameworks most effectively.
By uncovering hidden business logic, enterprises create a foundation for innovation that competitors may struggle to replicate. Institutional knowledge becomes a strategic asset rather than a hidden liability.
This creates a sustainable competitive advantage with AI through:
Helping teams move faster with clearer insights and decisions.
Reducing manual effort by making automation more accurate and useful.
Improving customer experiences through faster, more consistent service delivery.
Giving teams flexibility to respond quickly when priorities change.
Protecting business continuity by keeping important knowledge accessible.
How Prolifics Helps Organizations Unlock Hidden Business Logic
At Prolifics, we help organizations uncover, document, and operationalize hidden business logic across legacy systems, applications, workflows, and institutional knowledge sources.
Our approach combines AI-powered discovery, modernization expertise, process analysis, and enterprise architecture capabilities to help organizations:
Identify critical business rules embedded in legacy systems.
Preserve institutional knowledge before it is lost.
Accelerate software migration and modernization initiatives.
Improve operational efficiency and governance.
Build stronger foundations for enterprise AI and automation.
By transforming hidden business logic into actionable intelligence, organizations can reduce risk, improve agility, and unlock new opportunities for growth.
Conclusion
Hidden business logic represents one of the most significant yet overlooked assets within modern enterprises. Buried inside legacy systems, undocumented workflows, and employee expertise, this knowledge influences critical business decisions every day.
As organizations invest in digital transformation, automation, and enterprise AI, understanding and preserving this operational knowledge becomes increasingly important. AI provides powerful capabilities for discovering, documenting, and leveraging hidden business logic at scale.
Organizations that act now can strengthen business continuity, improve knowledge retention, accelerate modernization efforts, and create a lasting competitive advantage with AI. The ability to transform hidden knowledge into actionable intelligence will be a defining factor in future business success.
How does AI uncover tacit knowledge in business processes?
AI tools analyze legacy source code, documentation repositories, emails, support tickets, and structured interviews with subject matter experts. Machine learning models identify patterns, decision rules, and workflow logic that would otherwise require months of manual discovery making AI process intelligence faster and more accurate than traditional audits.
What are the hidden operational inefficiencies AI can detect?
AI can detect redundant manual steps, undocumented exception-handling rules, inconsistent data transformation logic, shadow IT processes, and informal approval chains. These inefficiencies often remain invisible until AI-powered analysis surfaces them from system logs, code repositories, and unstructured communications across the enterprise.
How does turning institutional knowledge into AI competitive advantage work?
When enterprises codify undocumented knowledge into structured process maps, knowledge graphs, and governance frameworks, they create AI training assets that competitors cannot easily replicate. This proprietary operational context improves model accuracy, accelerates automation, and builds a compound competitive advantage that deepens over time.
What AI strategy should enterprises use for codifying undocumented business rules?
Enterprises should start with a legacy system audit using AI code analysis tools, followed by unstructured data mining from documents and communications. Next, AI-assisted knowledge capture sessions with subject matter experts help fill gaps. The final step is operationalizing findings into centralized knowledge repositories that continuously feed enterprise AI and automation platforms.
As artificial intelligence adoption accelerates across industries, security leaders are facing a growing challenge: how to secure AI agents, machine identities, and automated workflows without slowing innovation. Amazon Web Services (AWS) is addressing this with new AWS AI security identity tools designed to close emerging security gaps in enterprise environments.
The latest AWS security enhancements focus on what experts increasingly call the “new attack surface,” non-human identities. AI agents, automated bots, APIs, and machine-driven workflows are rapidly proliferating across cloud ecosystems, creating new risks of unauthorized access, privilege escalation, and data exposure.
Industry reports indicate that many organizations remain overconfident in their AI security readiness despite lacking foundational identity governance controls. Security analysts warn that AI adoption is outpacing traditional identity management strategies, especially as enterprises scale autonomous systems.
To address these concerns, AWS has introduced advanced identity and access management capabilities that improve how AI agents authenticate, access systems, and interact with enterprise applications. Among the key innovations is AgentCore Identity, which provides enhanced access controls for AI agents and restricts interactions based on user permissions and organizational policies.
AWS is also integrating AI-driven automation into threat detection and security operations. New machine learning-powered security capabilities can automatically identify suspicious activity, detect multi-stage attacks, and correlate threats across cloud workloads in real time. These innovations aim to help organizations move from reactive security models to proactive, intelligent defense systems.
The importance of identity-centric security is becoming increasingly evident as enterprises embrace agentic AI architectures. AWS recently expanded its collaboration ecosystem around identity governance, with leading identity security providers such as SailPoint working closely with AWS to develop unified governance frameworks for both human and machine identities.
For enterprises, however, adopting these technologies is only part of the equation. Successfully implementing AI security requires a strategic partner capable of aligning cloud infrastructure, governance frameworks, compliance, and operational automation.
This is where Prolifics delivers value.
As a trusted digital transformation and cloud modernization partner, Prolifics helps organizations securely adopt AI-driven technologies while maintaining strong governance and operational resilience. From cloud-native identity management and zero-trust architectures to AI-enabled automation and security modernization, Prolifics enables enterprises to build scalable and secure AI ecosystems.
With deep expertise across AWS cloud services, AI integration, cybersecurity, and enterprise modernization, Prolifics helps organizations:
Modernize identity and access management frameworks
Secure AI agents and automated workflows
Implement cloud-native security architectures
Strengthen compliance and governance strategies
Accelerate AI adoption without compromising security
As AI becomes deeply embedded into enterprise operations, identity security will play a defining role in business resilience and digital trust. Organizations that proactively modernize their security posture today will be better positioned to innovate confidently tomorrow.
To learn how your organization can securely scale AI initiatives with AWS and advanced identity governance strategies, connect with Prolifics today.
Wildfires are no longer seasonal threats, they have become year-round disasters impacting utilities, governments, businesses, and communities worldwide. Climate volatility, aging utility infrastructure, extreme weather conditions, and expanding urban development near forests have significantly increased the frequency and intensity of wildfire incidents. For utility providers, especially energy and transmission companies, the stakes are higher than ever. A single ignition event can lead to catastrophic environmental destruction, regulatory penalties, financial liability, and public safety crises.
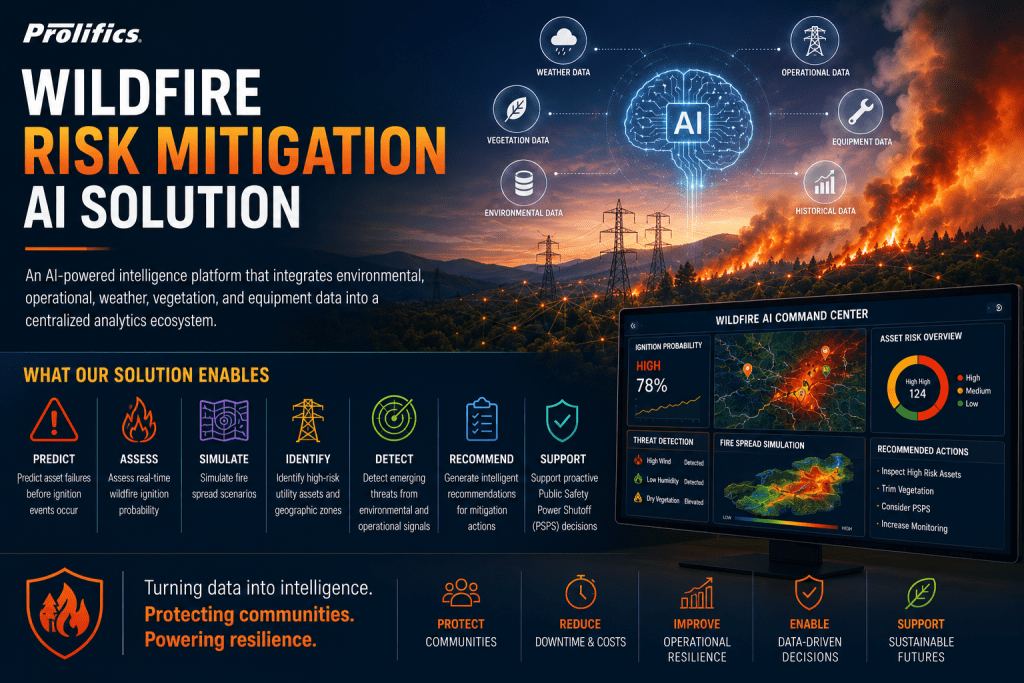
To address this growing challenge, Prolifics is pioneering an advanced wildfire risk prediction AI and Risk Mitigation AI Solution that combines Artificial Intelligence (AI), Machine Learning (ML), geospatial intelligence, weather analytics, and operational data into a unified decision-making platform. The solution empowers organizations to predict, prevent, and proactively respond to wildfire risks before they escalate into disasters.
The Growing Need for AI in Wildfire Management
Traditional wildfire mitigation approaches are reactive. Most organizations depend on static weather reports, fragmented operational systems, manual inspections, or historical observations to make critical decisions. However, wildfire conditions evolve rapidly and require real-time intelligence.
Several major challenges continue to delay wildfire management:
Escalating wildfire risks caused by climate volatility and prolonged droughts
Aging utility infrastructure vulnerable to ignition events
Fragmented datasets across GIS systems, weather platforms, operational tools, and vegetation monitoring systems
Inability to use historical trends effectively for predictive insights
Increasing regulatory scrutiny and liability exposure
Prolifics recognized that organizations needed more than isolated monitoring tools. They needed an intelligent platform capable of reasoning across multiple data sources, understanding wildfire patterns, and generating actionable insights to take quick decisions in real time.
Introducing the Prolifics Risk Mitigation AI Solution
The Prolifics Risk Mitigation AI Solution is an AI-powered intelligence platform and predictive wildfire analytics platform that integrates environmental, operational, weather, vegetation, MET, and equipment data into a centralized analytics ecosystem.
The platform enables organizations to:
Predict outages caused by asset failures before ignition events occur
Assess real-time wildfire and wildfire spread probability
Identify high-risk utility assets and geographic zones
Detect emerging threats from environmental and operational signals
Generate intelligent recommendations for mitigation actions
Support proactive Public Safety Power Shutoff (PSPS) decisions
At its core, the solution leverages AI-driven reasoning engines that can process complex user queries in natural language. Business users no longer need deep technical expertise or database knowledge to access critical wildfire intelligence.
As discussed during solution planning sessions, the system was designed so that even newly onboarded personnel can ask straightforward questions based on user personas and pre-defined IAM privileges and receive intelligent answers without needing to understand underlying schemas or technical structures.
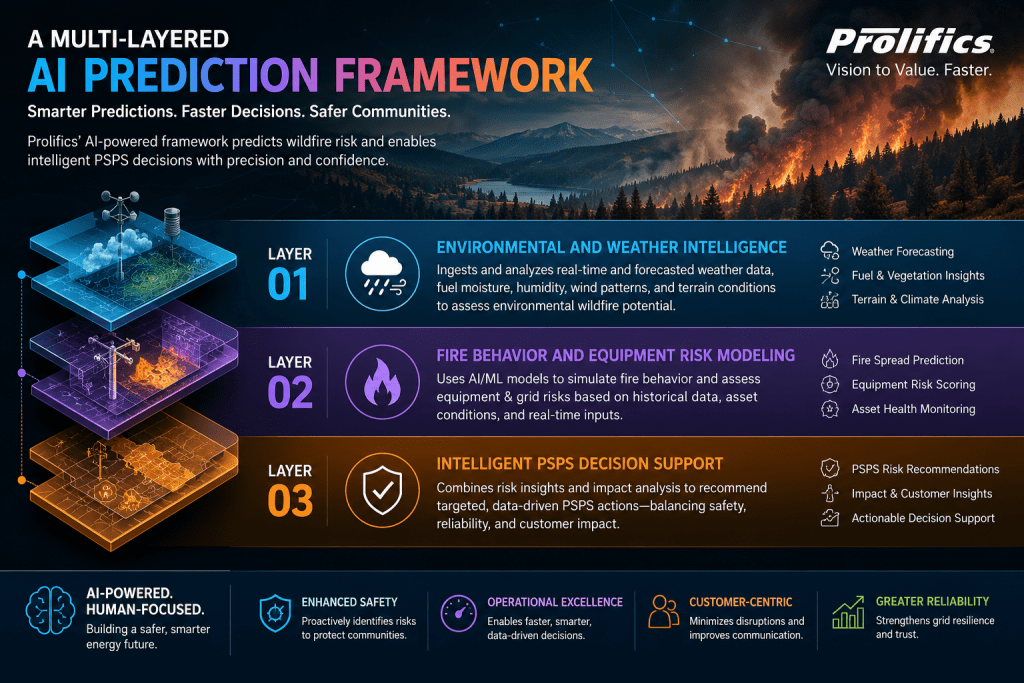
A Multi-Layered AI Prediction Framework
The Prolifics solution operates through a sophisticated three-layer wildfire prediction architecture.
Layer 1: Environmental and Weather Intelligence
The first layer focuses on weather conditions, atmospheric instability, fuel moisture, vegetation stress, and terrain analysis.
The system continuously evaluates critical wildfire indicators such as:
Relative humidity
Wind speed and wind gust behavior
Air temperature across multiple elevations
Vapor pressure deficit
Solar radiation
Soil moisture
Dead and live fuel moisture
Vegetation dryness indexes
Terrain ruggedness and slope
These variables are essential because wildfire ignition and spread are highly dependent on environmental conditions. For example:
Critically low vegetation moisture creates explosive fire conditions
The platform processes these parameters dynamically to assess fire susceptibility at granular geographic levels.
Layer 2: Fire Behavior and Equipment Risk Modeling
The second layer introduces advanced fire behavior simulations and utility asset risk analysis.
This layer evaluates:
Probability of catastrophic fire behavior
Fire spread rate
Predicted flame length
Potential fire footprint
Equipment failure probability
Vegetation-related ignition risks
Tree-strike probabilities
Infrastructure vulnerabilities
One of the most powerful capabilities is the Catastrophic Fire Probability (CFPt) scoring mechanism. The platform calculates risk scores using equipment conditions, vegetation exposure, and environmental variables as shared by MET to determine whether a specific asset or transmission section could trigger catastrophic wildfire conditions.
The system also evaluates induction risks, vegetation hazards, unresolved maintenance tags, and structural risks associated with utility poles and transmission infrastructure.
This comprehensive intelligence enables utility operators to prioritize high-risk assets before failures occur.
Layer 3: Intelligent PSPS Decision Support
Public Safety Power Shutoff (PSPS) programs are critical wildfire mitigation measures used by utility companies during extreme fire weather conditions. However, unnecessary power outages can significantly impact businesses, hospitals, schools, and communities.
The third layer of the Prolifics solution provides intelligent PSPS decision support by combining environmental risk scores, fire behavior analysis, asset intelligence, and operational thresholds.
The platform determines:
Whether minimum fire potential conditions are met
Which transmission lines require scoping
High Fire Risk Area classifications
Operational risk levels
Regulatory tier designations
Final scoping decisions for utility operations
This allows organizations to make faster, defensible decisions supported by AI-generated insights and predictive analytics.
AI-Powered Conversational Intelligence
One of the most innovative aspects of the solution is its conversational AI capability. The platform uses Large Language Models (LLMs) to translate business questions into intelligent SQL queries dynamically. Instead of relying on predefined dashboards alone, users can ask complex questions naturally, such as:
“Which transmission assets are at highest wildfire risk today?”
“Show assets within five miles of catastrophic fire zones.”
“Identify unresolved vegetation risks in high wind regions.”
The AI engine reasons through the query, generates multiple SQL queries if needed, retrieves the required data, and constructs an intelligent response for the user.
The architecture was further enhanced with:
Multi-query reasoning workflows
Distance calculation capabilities for nearby asset analysis
Contextual memory to retain previous interactions
Simplified UI experiences for business users
Collapsible technical outputs for developers and engineers
Asset history based on audit files
This creates a highly intuitive experience while still maintaining advanced technical depth behind the scenes.
Synthetic Data and Machine Learning Innovation
To improve predictive accuracy, the Prolifics team designed realistic synthetic wildfire scenarios categorized into:
Safe
Near-miss
Dangerous
Catastrophic
Each scenario includes realistic environmental and operational parameter ranges based on wildfire domain expertise.
The system generated over 5,000 synthetic records using weighted formulas that combined:
Weather conditions
Fuel moisture
Equipment failure probabilities
Vegetation risk factors
This approach improves AI model reliability while enabling scalable testing and simulation capabilities.
Business Impact and Executive Value
The Prolifics wildfire Risk Mitigation AI Solution delivers measurable business value across operations, compliance, and risk management.
Reduced Risk Exposure
Organizations can proactively identify wildfire-prone assets and geographic zones before incidents occur.
Wildfire management is entering a new era driven by predictive intelligence, automation, and AI-powered operational awareness. Organizations can no longer depend solely on manual monitoring or isolated systems to address increasingly complex wildfire threats.
The Prolifics Wildfire Risk Mitigation AI Solution represents a transformative shift toward intelligent wildfire prevention, where data, AI, and operational intelligence work together to protect communities, infrastructure, and the environment.
By combining machine learning, geospatial intelligence, conversational AI, and predictive analytics, Prolifics is helping organizations move from reactive firefighting to proactive wildfire prevention.
In a world where every second matters, AI-powered wildfire intelligence could mean the difference between containment and catastrophe.
About the Author: Swati Dora is an Associate Director at Prolifics specializing in AI-driven enterprise transformation, predictive analytics, and intelligent solutions for utility and industrial organizations.
Frequently Asked Questions (FAQs)
1. What is an AI-powered wildfire management solution?
An AI-powered wildfire Risk Mitigation AI Solution technologies such as machine learning, predictive analytics, weather intelligence, geospatial analytics, and real-time monitoring to identify wildfire risks before ignition occurs. These platforms help utilities and infrastructure providers predict equipment failures, assess fire spread probability, and optimize emergency response strategies.
2. How does Prolifics’ Risk Mitigation AI Solution help utility companies?
Prolifics’ Risk Mitigation AI Solution helps utility companies reduce wildfire risks by combining weather data, vegetation analysis, infrastructure monitoring, and AI-based predictive modeling into a unified platform. The solution enables utilities to proactively identify high-risk assets, improve PSPS decision-making, optimize maintenance activities, and reduce operational and regulatory exposure.
3. What types of data are used in wildfire prediction models?
Wildfire prediction models use multiple data sources, including: * Weather and atmospheric conditions * Wind speed and humidity * Fuel moisture levels * Vegetation density * Terrain and geospatial data * Infrastructure health metrics * Equipment failure probabilities * Sensor and operational data By analyzing these variables together, AI models can accurately predict wildfire ignition and spread risks.
4. Can AI improve Public Safety Power Shutoff (PSPS) decisions?
Yes. AI significantly improves PSPS decision-making by providing real-time risk assessments and predictive insights. Instead of implementing broad power outages, utilities can make targeted shutoff decisions based on wildfire probability, equipment risk, environmental conditions, and fire behavior simulations. This reduces unnecessary outages while improving public safety.
5. Why is predictive wildfire intelligence important for the future?
Predictive wildfire intelligence enables organizations to move from reactive firefighting to proactive wildfire prevention. As climate change increases the frequency and severity of wildfires, AI-driven systems provide faster decision-making, improved operational resilience, reduced liability exposure, and better protection for communities, infrastructure, and natural resources.
Agentic AI is a new class of artificial intelligence that can independently plan, decide, act, and adapt to achieve business goals with minimal human intervention. Unlike traditional AI systems that respond to prompts or predefined workflows, Agentic AI combines reasoning, memory, orchestration, and autonomous execution to manage complex enterprise tasks across applications, data systems, and business processes.
As enterprises accelerate digital transformation, Agentic AI is emerging as the next major shift after cloud computing and automation. It enables organizations to move from reactive systems to intelligent operational ecosystems capable of autonomous IT management, customer engagement, workflow optimization, and decision support at enterprise scale.
Quick answer: Agentic AI refers to autonomous AI systems that can understand goals, make decisions, execute multi-step actions, and continuously learn from outcomes. Enterprises are adopting Agentic AI to improve enterprise automation, reduce operational costs, accelerate decision-making, modernize IT operations, and create intelligent business workflows across finance, healthcare, retail, insurance, and public sector environments.
What Is Agentic AI?
Agentic AI is an AI architecture designed to operate with autonomy, contextual awareness, reasoning, and goal-driven execution. Instead of waiting for human instructions at every step, Agentic AI systems can interpret objectives, plan workflows, coordinate tools or applications, and dynamically adjust actions based on outcomes.
Traditional AI models primarily generate outputs based on prompts. Agentic AI systems go further by independently managing sequences of actions. For example, an enterprise AI agent could monitor cloud infrastructure, identify performance issues, open service tickets, trigger remediation workflows, notify stakeholders, and generate audit reports without requiring manual intervention.
Agentic AI is an enterprise AI approach where autonomous software agents can reason, plan, act, and adapt across systems to achieve defined business objectives with limited human oversight. These systems combine generative AI, automation, analytics, and orchestration technologies to enable intelligent enterprise operations.
According to Gartner, autonomous and agent-based AI systems are expected to become a foundational capability for enterprise operations and digital business transformation over the next several years.
Why Is Agentic AI the Next Big Enterprise Shift?
Agentic AI is becoming the next major enterprise shift because organizations are reaching the limits of traditional automation and fragmented AI deployments. Enterprises need systems that can operate across siloed data environments, make contextual decisions, and continuously optimize operations without constant human supervision.
Several business drivers are accelerating adoption:
1. Enterprise Complexity Is Increasing
Modern enterprises operate across hybrid cloud environments, SaaS applications, legacy systems, APIs, and distributed data ecosystems. Managing these environments manually creates operational inefficiencies and delays.
Agentic AI introduces intelligent orchestration that can coordinate actions across multiple systems in real time.
2. Traditional Automation Has Limitations
Robotic Process Automation (RPA) and rules-based workflows depend heavily on predefined conditions. They struggle with ambiguity, dynamic decision-making, and unstructured data.
Agentic AI combines reasoning and adaptability with automation, enabling systems to handle exceptions, changing conditions, and multi-step enterprise workflows.
3. Businesses Need Faster Decision-Making
Enterprises increasingly rely on real-time analytics, predictive insights, and operational intelligence. Agentic AI can analyze enterprise data continuously and execute actions faster than human-led processes.
4. Generative AI Created the Foundation
The rise of LLMs and generative AI platforms made natural language interaction scalable. Agentic AI extends this capability by adding planning, execution, and enterprise workflow integration.
According to IBM, organizations adopting AI-driven automation can significantly improve operational efficiency while reducing repetitive manual work across IT and business operations.
How Does Agentic AI Work in Enterprise Environments?
Agentic AI works by combining AI reasoning engines, enterprise data systems, automation frameworks, and orchestration layers into a unified operational model. These systems operate similarly to human teams but at machine speed and enterprise scale.
A typical agentic AI workflow includes:
Understanding a business objective
Accessing enterprise data sources
Creating an execution plan
Coordinating actions across systems
Monitoring outcomes
Adjusting workflows dynamically
Reporting results and learning continuously
For example, in a healthcare environment, an agentic AI system could:
Analyze patient intake data
Identify missing insurance information
Trigger verification workflows
Schedule appointments
Recommend next-best clinical actions
Generate compliance documentation
Alert care teams about risks
This level of autonomous coordination reduces administrative burden while improving patient experience and operational efficiency.
In financial services, Agentic AI can support fraud detection by continuously monitoring transactions, identifying anomalies, escalating suspicious activities, generating compliance records, and initiating remediation workflows automatically.
What Is the Difference Between Traditional AI and Agentic AI?
Capability
Traditional AI
Agentic AI
Interaction Model
Prompt-response
Goal-driven execution
Workflow Handling
Single task focused
Multi-step orchestration
Decision-Making
Limited
Contextual and adaptive
Autonomy
Low
High
Learning Capability
Static or periodic
Continuous feedback-based
Enterprise Integration
Partial
Deep cross-system integration
Automation Scope
Task automation
End-to-end enterprise automation
Human Dependency
Frequent intervention
Minimal oversight
Traditional AI systems are effective for prediction, classification, and content generation. Agentic AI introduces operational intelligence capable of independently managing enterprise processes.
This shift is similar to the evolution from isolated applications to cloud-native enterprise platforms. Organizations are no longer looking for standalone AI tools; they need intelligent operational ecosystems.
How Are Enterprises Using Agentic AI Today?
Enterprises across industries are already deploying Agentic AI for high-value operational use cases.
Healthcare
Healthcare providers are using AI agents for patient scheduling, claims processing, clinical documentation, diagnostic assistance, and care coordination. Autonomous workflows help reduce administrative overhead and improve patient outcomes.
Financial Services
Banks and insurance providers use Agentic AI for fraud detection, risk modeling, underwriting support, customer service automation, and compliance management.
Retail
Retail organizations deploy intelligent AI agents for inventory optimization, supply chain coordination, personalized customer engagement, and dynamic pricing strategies.
Public Sector
Government agencies are exploring Agentic AI for citizen service automation, case management, document processing, and operational modernization initiatives.
A Prolifics-relevant enterprise use case involves integrating Agentic AI with hybrid cloud infrastructure and enterprise data platforms to automate IT service management. AI agents can monitor infrastructure performance, identify anomalies, trigger remediation workflows, and improve system resilience without manual escalation.
According to Forrester, enterprises increasingly prioritize AI systems that combine automation, orchestration, and operational intelligence to support large-scale business transformation initiatives.
Which Technologies Power Agentic AI?
Agentic AI depends on a combination of modern enterprise technologies working together as an integrated ecosystem.
Key enabling technologies include the following:
Large Language Models (LLMs)
Enterprise AI platforms
Workflow orchestration engines
Cloud-native infrastructure
API management platforms
Vector databases and knowledge retrieval
Data integration frameworks
Machine learning operations (MLOps)
Enterprise security and governance tools
Cloud migration and system integration are critical enablers because Agentic AI relies heavily on real-time data access and interoperability across enterprise applications.
Organizations with fragmented infrastructure, disconnected data systems, or limited governance maturity may struggle to scale Agentic AI initiatives effectively.
This is why many enterprises focus first on data readiness, IT modernization, API integration, and cloud transformation before implementing autonomous AI systems.
How Can Enterprises Implement Agentic AI Successfully?
Successful Agentic AI adoption requires more than deploying AI models. Enterprises need a structured modernization strategy that aligns technology, governance, operations, and business goals.
Define high-value business outcomes Identify operational bottlenecks, customer experience gaps, or workflow inefficiencies where autonomous AI can create a measurable impact.
Modernize enterprise data infrastructure Ensure enterprise data is accessible, integrated, governed, and real-time ready.
Build secure integration frameworks Create API-first architectures that allow AI agents to interact safely across systems and applications.
Establish governance and oversight Implement monitoring, compliance, security controls, explainability standards, and human review processes.
Start with targeted use cases Deploy Agentic AI in specific operational areas before scaling enterprise wide.
Continuously optimize workflows Monitor outcomes, retrain models, refine orchestration logic, and improve business alignment over time.
Enterprises that approach Agentic AI strategically are more likely to achieve scalable operational transformation rather than isolated pilot successes.
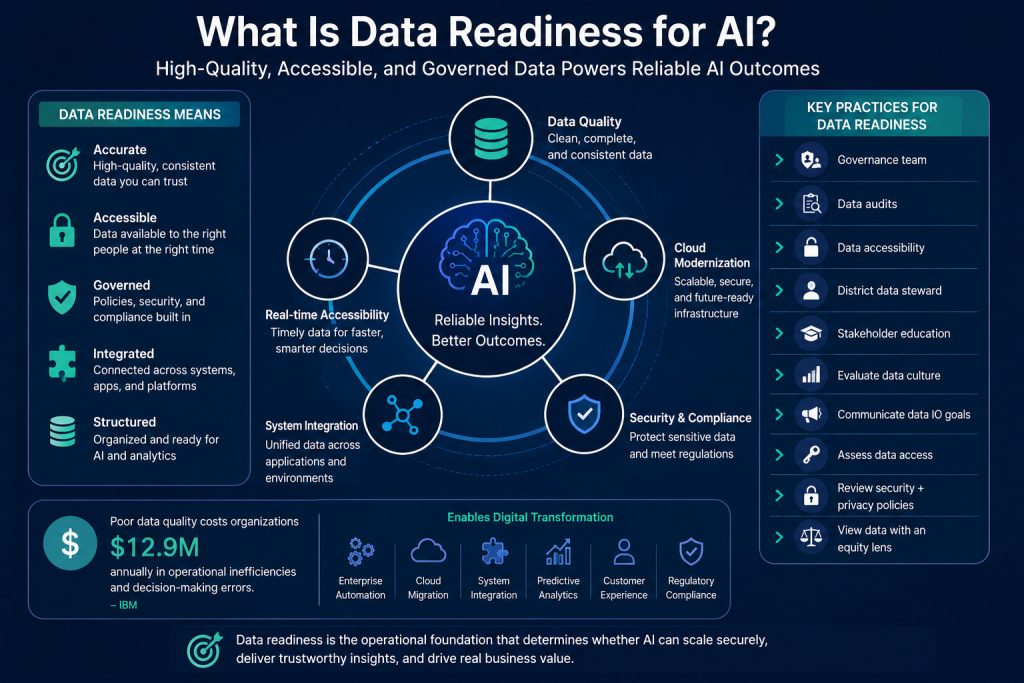
Why Does Data Readiness Matter for Agentic AI?
Agentic AI systems are only as effective as the enterprise data environments supporting them. Poor data quality, fragmented systems, and inconsistent governance can significantly reduce the accuracy and reliability of autonomous decision-making.
Agentic AI requires:
Unified enterprise data access
Real-time analytics capabilities
Metadata governance
Strong cybersecurity controls
Scalable cloud infrastructure
High-quality structured and unstructured data
According to IBM research, poor data quality costs organizations trillions of dollars annually through inefficiencies, compliance risks, and operational failures. Reliable enterprise AI systems require trusted, governed, and integrated data ecosystems.
For organizations pursuing digital transformation, data modernization becomes a foundational requirement for scaling autonomous AI initiatives successfully.
FAQ
What is Agentic AI in simple terms?
Agentic AI is an advanced form of artificial intelligence that can independently make decisions, complete tasks, and adapt workflows to achieve business goals. Unlike standard AI tools that only respond to prompts, Agentic AI systems can manage complex enterprise processes with limited human intervention.
How is agentic AI different from generative AI?
Generative AI primarily creates content such as text, images, or code based on prompts. Agentic AI combines generative AI with reasoning, planning, memory, orchestration, and autonomous execution to complete multi-step operational tasks across enterprise systems.
Which industries benefit most from Agentic AI?
Industries with complex operations and large-scale workflows benefit significantly from Agentic AI, including healthcare, finance, retail, insurance, manufacturing, and public sector organizations. Common use cases include enterprise automation, fraud detection, IT operations, customer service, and workflow orchestration.
What are the biggest challenges in implementing Agentic AI?
The main challenges include poor data readiness, fragmented systems, governance concerns, security risks, integration complexity, and lack of operational alignment. Enterprises must modernize infrastructure and establish strong governance frameworks before scaling autonomous AI initiatives.
Is Agentic AI replacing human workers?
Agentic AI is primarily designed to augment human teams rather than replace them entirely. It automates repetitive and operational tasks, enabling employees to focus on strategic decision-making, innovation, customer engagement, and high-value business activities.
Conclusion
Agentic AI represents a major evolution in enterprise technology by combining autonomous reasoning, workflow orchestration, and operational intelligence into scalable business systems. Organizations are moving beyond isolated AI deployments toward intelligent ecosystems capable of managing complex workflows, accelerating decision-making, and improving enterprise efficiency.
As digital transformation initiatives continue to expand, enterprises that modernize their data infrastructure, cloud environments, and integration strategies will be better positioned to scale Agentic AI successfully. The shift toward autonomous enterprise operations is already underway across healthcare, finance, retail, insurance, and public sector environments.
Prolifics helps enterprises build the modern data, integration, cloud, and AI foundations required to implement Agentic AI at scale through secure, enterprise-grade digital transformation strategies.
Every enterprise today sits on a goldmine of data, yet most of it remains locked inside systems that were never designed to power intelligent applications. As AI adoption accelerates across industries, the gap between raw data infrastructure and AI-ready architecture has become one of the most pressing technical challenges for modern organizations.
At Prolifics, we help enterprises bridge that gap, transforming legacy data pipelines into intelligent, AI-native infrastructure that delivers real business value at speed.
The Legacy Data Pipeline Landscape
Most enterprise data environments were built for a different era. Batch ETL workflows, siloed data warehouses, and reporting-oriented BI stacks served organizations well in a world where insight meant a weekly dashboard. Today, those same architectures create bottlenecks that directly block enterprise AI adoption at scale.
Auditing your current stack means asking hard questions about latency, flexibility, and readiness. To understand where legacy architectures fall short, consider the following:
Batch ETL processes introduce 24-hour data delays for AI models.
Siloed warehouses prevent unified access across enterprise data sources.
BI stacks optimize for human reports, not machine consumption.
Schema-on-write systems struggle with unstructured and semi-structured data.
Tightly coupled pipelines make it costly to add new AI workloads quickly.
These architectural gaps do not just slow delivery; they fundamentally limit what AI systems can learn, infer, and act on in production environments.
Defining the AI-Ready Pipeline
An AI-ready pipeline is architecturally different from its reporting-oriented predecessor. Where traditional pipelines move data from source to destination for human analysis, AI pipelines must serve models with low latency, contextual memory, and continuous feedback loops. Understanding this distinction is essential before any enterprise begins its data to AI pipeline migration.
Core architectural principles that define an AI-ready pipeline include three foundational elements:
Real-time feature serving keeps model inputs fresh and contextually accurate.
Embedding pipelines convert raw data into dense, semantically rich vector representations.
Model-in-the-loop design allows AI outputs to influence downstream pipeline decisions dynamically.
These principles shift the pipeline from a passive data mover to an active participant in intelligent workflows, creating the foundation for sustainable and scalable AI acceleration.
AI Acceleration
1. Unified Ingest for AI Workloads
One of the most common bottlenecks in enterprise AI pipeline implementation is fragmented data ingestion. When structured transactional records, unstructured documents, and real-time event streams flow through separate pipelines, AI models face an incomplete and inconsistent view of the business. Building a unified ingest fabric resolves this by consolidating all data types into a single ingestion layer that any model can access with minimal latency.
Consolidating ingest at the architectural level produces outcomes that significantly accelerate AI adoption across the enterprise:
Unified schemas reduce data transformation overhead for every new AI model.
Real-time event ingestion enables models to respond to live business signals.
Streaming and batch ingestion coexist without separate engineering teams managing each.
Unstructured content including PDFs, emails, and logs enters the same pipeline as structured records.
Any enterprise data source becomes accessible to AI workloads without custom connectors.
This approach converts your data infrastructure into an AI-accessible fabric, removing the last-mile friction that often delays time-to-production for new models.
2. Feature Stores and Vector Databases
As enterprises scale up their AI initiatives, they quickly discover that raw data alone is insufficient for model performance. AI models require pre-computed, consistently formatted inputs delivered at millisecond speeds. This is where the AI memory layer becomes critical, consisting of feature stores for structured model inputs and vector databases for semantic retrieval.
Dimension
Feature Store
Vector Database
Primary purpose
Manage, store, and serve pre-computed ML features for predictive models.
Store and retrieve high-dimensional vector embeddings for semantic search and RAG.
Predictive ML models that rely on structured, frequently updated business signals.
Generative AI applications that need grounding in proprietary enterprise knowledge and context.
Together, these two components form a robust AI memory layer. Feature stores provide consistency and speed for predictive models, while embedding registries and vector search infrastructure power generative AI applications. Building this layer early reduces the cost and complexity of every AI workload that follows.
LLM-in-the-Loop Pipeline Acceleration
One of the most transformative shifts in modern AI pipeline architecture is using large language models not just as endpoints but as active participants in the pipeline itself. Embedding generative AI directly into data preparation stages compresses timelines that traditionally took weeks into hours, dramatically reducing time-to-AI for enterprise data teams.
LLMs bring intelligence to tasks that previously required extensive manual engineering:
Auto-labeling assigns semantic tags to unlabeled datasets without human intervention.
Schema inference generates structured metadata from raw, unstructured data sources.
Semantic classification categorizes records based on meaning rather than rigid rules.
Code generation writes transformation logic, reducing data engineering cycle time significantly.
Anomaly narration produces human-readable explanations for unusual data patterns automatically.
Now see how embedding LLMs into your pipeline compresses weeks of manual data preparation into hours; click each stage to explore the time savings.
When enterprises embed LLMs into their pipeline operations, they stop treating AI as the final step in a long process and start treating it as an accelerant throughout the entire data lifecycle.
Governance and Scale
Observability, Quality, and Model Monitoring
Why It Matters?
AI pipelines without observability are production liabilities. Unlike traditional software where bugs produce deterministic errors, AI pipelines fail silently. A model can continue to produce outputs while gradually drifting away from accuracy, and without the right monitoring infrastructure, that drift goes undetected until it causes real business harm.
Maintaining trust in AI outputs at enterprise scale demands closed-loop feedback mechanisms, not just point-in-time validation. Organizations operating across global footprints need observability frameworks that cover the full pipeline lifecycle, from ingest quality to model output reliability.
Effective observability covers three critical dimensions:
Data drift detection flags when incoming data distributions shift unexpectedly over time.
End-to-end data lineage traces every record from its source to its model output.
SLA tracking ensures AI pipelines meet latency and freshness commitments reliably.
Without this layer, responsible AI deployment remains aspirational rather than operational.
Enterprise Governance and Responsible AI
Governance cannot be a retrofitted concern. When privacy handling, bias mitigation, and regulatory compliance get added after deployment, they create fragile controls that break under scale. For enterprises with global operations, embedding governance at the ingest layer is the only architecture that holds.
Prolifics designs AI pipeline governance frameworks that satisfy regulatory requirements across multiple jurisdictions simultaneously:
PII detection and masking runs at ingest, not at reporting, reducing downstream exposure risk.
Bias evaluation checkpoints run at feature creation and model training stages consistently.
GDPR and DPDP compliance controls govern data residency, consent, and deletion workflows.
SOC 2 audit trails capture every pipeline action with tamper-evident logging automatically.
Role-based access controls restrict sensitive data exposure to authorized model and team usage.
Treating governance as a first-class architectural component rather than a compliance overlay ensures that AI systems earn and maintain the trust of regulators, customers, and the enterprise itself.
Conclusion
The journey from data pipelines to AI pipelines is not a lift-and-shift migration. It demands a deliberate architectural evolution, one that replaces batch-oriented, report-driven infrastructure with real-time, model-ready systems built for continuous learning and generative intelligence. The enterprises that move fastest are those that unify their ingest layer, build a scalable AI memory layer through feature stores and vector databases, accelerate data preparation with LLM-in-the-loop processing, and embed governance from day one.
Prolifics brings the engineering depth, enterprise experience, and end-to-end AI pipeline expertise to help organizations achieve this transformation at speed. Whether you are at the audit stage or ready to scale production AI workloads, our teams are equipped to accelerate every step of the journey.
Microsoft has taken another bold step into the open-source ecosystem with the release of Azure Linux 4.0, its first enterprise-focused server Linux distribution designed specifically for cloud, AI, and containerized workloads. The announcement, revealed during Open-Source Summit North America 2026, signals how deeply Microsoft has embraced Linux and open-source technologies after years of being viewed as a Windows-first company.
The launch has generated significant buzz across the technology industry because it reflects Microsoft’s rapidly evolving approach toward cloud infrastructure and enterprise computing. Over the past decade, the company has steadily increased its investments in Linux, Kubernetes, containers, and developer-focused open-source tools. Azure Linux 4.0 appears to be the next major milestone in that transformation.
Azure Linux 4.0 is an evolution of Microsoft’s earlier internal Linux project known as CBL-Mariner, which was rebranded as Azure Linux in 2024. The new version is built to support Azure’s massive infrastructure, modern AI-native applications, edge computing, and cloud-native environments. According to Microsoft, the platform delivers a hardened, lightweight, and highly secure operating system optimized for virtual machines, containers, and enterprise-scale deployments.
One of the biggest highlights of Azure Linux 4.0 is its focus on AI infrastructure. As enterprises continue to invest heavily in generative AI and machine learning systems, the need for secure and scalable operating systems has become increasingly important. Microsoft says Azure Linux 4.0 is designed to support demanding AI workloads while simplifying infrastructure management for organizations operating at scale.
Another important aspect of the release is its emphasis on operational consistency. Microsoft explained that Azure Linux 4.0 is engineered to create a unified environment between Azure Virtual Machines and container-based workloads. This consistency can help enterprises reduce compatibility issues, improve deployment speed, and simplify maintenance across hybrid and multi-cloud environments.
The company also confirmed that Azure Linux 4.0 will soon enter public preview for Azure Virtual Machines, while Azure Container Linux has already reached general availability. These distributions are intended to provide consistency between host operating systems and container environments, which has become increasingly important for AI applications and distributed systems.
Industry experts believe Microsoft’s move could intensify competition within the enterprise Linux market. Companies such as Red Hat, Canonical, SUSE, and Rocky Linux have traditionally dominated enterprise server environments. However, Microsoft’s direct integration with Azure cloud services may provide a unique advantage for businesses already invested in the Microsoft ecosystem.
Beyond infrastructure modernization, Microsoft is also aligning the launch with its broader AI ambitions. During Open-Source Summit North America 2026, the company introduced several initiatives focused on agentic AI systems. Microsoft announced collaborations with the open-source community and technology partners to create standardized frameworks that allow AI agents from different vendors to communicate and operate together seamlessly.
This announcement demonstrates how Microsoft is positioning itself not just as a cloud provider, but as a leader in AI-native computing. By combining open-source technologies with enterprise-grade cloud infrastructure, the company hopes to create platforms capable of supporting the next generation of intelligent applications and autonomous systems.
Security also remains a central theme in Azure Linux 4.0. Microsoft has incorporated Azure-specific security hardening, compliance capabilities, and optimized package management to ensure enterprise-grade protection. As cyber threats continue to evolve, businesses are increasingly demanding operating systems that can deliver both flexibility and robust security at scale.
Today, Microsoft actively contributes to open-source communities, supports Linux across Azure, and continues to invest heavily in collaborative innovation. Azure Linux 4.0 stands as clear evidence of how much the company’s philosophy has changed.
With this release, Microsoft is not just launching another Linux distribution. It is redefining its role in the open-source world and reinforcing its commitment to AI-driven cloud infrastructure. Azure Linux 4.0 could become a significant foundation for the next generation of enterprise AI and cloud-native computing.
Key Highlights of Azure Linux 4.0
Enterprise-grade Linux distribution built by Microsoft
Designed specifically for Azure cloud and AI workloads
Lightweight, secure, and optimized for containers
Supports AI-native and cloud-native applications
Based on Microsoft’s earlier CBL-Mariner project
Focused on consistency across VMs and containers
Includes Azure-specific security hardening features
Supports enterprise scalability and operational efficiency
Strengthens Microsoft’s position in open-source innovation
Aligns with Microsoft’s broader agentic AI initiatives
What This Means for Enterprise Technology Leaders
The launch of Azure Linux 4.0 reflects a broader shift toward AI-native infrastructure, cloud-native operations, and container-first architectures.
Organizations modernizing legacy systems or scaling enterprise Linux for AI workloads will increasingly require:
secure cloud foundations
unified container environments
scalable Kubernetes infrastructure
AI-ready DevOps ecosystems
This is where partners like Prolifics help enterprises accelerate modernization through:
Azure Linux 4.0 is an enterprise-grade Linux operating system developed by Microsoft specifically for cloud computing, AI workloads, and containerized environments. It is designed to support modern enterprise needs such as AI model deployment, microservices architecture, and large-scale distributed systems. Azure Linux 4.0 is optimized for Azure infrastructure, making it a strong choice for organizations building AI-native and cloud-native applications.
Is Azure Linux 4.0 open source?
Yes, Azure Linux 4.0 is open source. Microsoft has made the source code publicly available, allowing developers and enterprises to inspect, modify, and contribute to the platform. This aligns with Microsoft’s broader commitment to open-source innovation and collaboration. By making Azure Linux open source, Microsoft enables greater transparency, faster innovation, and improved security through community contributions.
What was Azure Linux previously called?
Azure Linux was previously known as CBL-Mariner, which was Microsoft’s internal Linux distribution used to power Azure services and infrastructure. In 2024, Microsoft rebranded CBL-Mariner to Azure Linux to reflect its broader enterprise focus and public availability. Azure Linux 4.0 builds on this foundation with enhanced security, scalability, and AI workload optimization.
Why did Microsoft create its own Linux distribution?
Microsoft developed Azure Linux to gain better control over performance, security, and consistency across its cloud infrastructure. Instead of relying on third-party distributions, it enables: 1. Optimized performance for Azure workloads 2. Built-in security hardening 3. Consistency across VMs and containers This helps enterprises achieve faster deployments, improved reliability, and scalable AI/cloud operations.
How is Azure Linux 4.0 different from Ubuntu or Red Hat?
Azure Linux 4.0 is designed specifically for Azure cloud and AI workloads, unlike general-purpose systems like Ubuntu or Red Hat. It provides deeper Azure integration, better optimization for containers and AI, and improved performance for cloud-native applications, making it ideal for organizations within the Microsoft ecosystem.
The utility sector is evolving rapidly as organizations balance sustainability goals, aging infrastructure, regulatory compliance, and rising customer expectations. To stay competitive, utilities need smarter operations, connected systems, and real-time intelligence that improve resilience while accelerating innovation. Prolifics empowers utility companies with AI-driven transformation, cloud modernization, intelligent automation, advanced analytics, and integration solutions designed to modernize operations and unlock measurable business value.
From smart grid modernization to renewable energy integration, Prolifics helps utility providers transform legacy environments into agile, scalable, and future-ready ecosystems. Our expertise enables organizations to improve operational visibility, optimize asset performance, strengthen cybersecurity, modernize customer experiences, and reduce downtime across the enterprise.
Why Utility Organizations Choose Prolifics
AI-powered predictive maintenance and intelligent operations
Real-time analytics for faster decision-making
Cloud migration and infrastructure modernization
Enterprise integration and API management
Intelligent automation for workflow optimization
Renewable energy and smart grid enablement
Enhanced cybersecurity and compliance readiness
Reduced operational costs and improved efficiency
Improved workforce productivity and customer engagement
Managed services and continuous optimization support
Proven Results Across the Energy Ecosystem
Prolifics has successfully helped utility and energy organizations improve operational visibility, integrate renewable energy into existing grids, streamline incident response management, and accelerate digital innovation through AI, automation, and advanced analytics.
Transform Utility Operations with Prolifics
Modernize your utility infrastructure, unlock data-driven intelligence, and build a resilient digital ecosystem prepared for the future of energy.
Download the Energy Sector Brochure
Explore how Prolifics delivers AI, cloud, automation, and data solutions for utility and energy organizations.
For enterprise CIOs and engineering leaders, the pressure is real: deliver faster, do more with less, and stay ahead of competitors already deploying AI-augmented engineering at scale. Software development is undergoing its third major revolution, and this time, the stakes are higher than ever.
The first era introduced manual coding. The second brought Agile, DevOps, and cloud-native architectures. Now, the third era is here: AI-augmented software development powered by agentic AI systems, intelligent copilots, and autonomous pipelines, and it is already reshaping how the world’s best engineering teams operate.
The conversation has shifted. It is no longer about whether AI will impact software engineering it already has. The real question is, how should your enterprise adapt to stay competitive in 2026 and beyond?
Despite headlines about AI replacing developers, the reality is far more strategic. AI is not eliminating engineering talent it is redefining how engineers work. At Prolifics, we believe the future of software development is not “fewer engineers,” but smarter engineers, empowered by AI.
What is AI-Augmented Engineering?
AI-augmented engineering is the integration of AI-powered tools, including coding copilots, agentic pipelines, and automated testing systems, into the software development lifecycle. It enables enterprise dev teams to accelerate delivery, reduce manual effort, and improve code quality while keeping human engineers in strategic control.
The Evolution Toward AI-Augmented Development: Why Traditional Dev is Falling Behind
Modern software development environments are becoming increasingly complex. Enterprises manage distributed systems, hybrid cloud environments, microservices architectures, APIs, cybersecurity requirements, and continuous delivery pipelines simultaneously. Traditional development approaches struggle to keep pace with rising customer expectations and shrinking delivery timelines.
This challenge has accelerated the rise of AI-powered engineering tools such as:
Generative AI and agentic AI models are now capable of performing tasks that once required significant manual effort. Developers can generate code snippets, automate repetitive tasks, detect vulnerabilities, and optimize workflows in real time.
However, enterprises are discovering that successful AI adoption is not simply about deploying AI tools; it requires a complete transformation of software engineering practices.
Are Agentic AI Pipelines Really Replacing Dev Teams? The Truth for Enterprise Leaders
The rapid advancement of agentic AI pipelines has sparked concern across the technology industry. Autonomous agents can now analyze requirements, generate code, execute tests, identify bugs, and even initiate deployments with minimal human intervention.
While this may sound like the replacement of development teams, the reality is more nuanced.
Where AI Excels:
Repetitive development and boilerplate code generation
Code optimization and refactoring
Pattern recognition and anomaly detection
Automated regression and unit testing
Documentation creation at scale
Workflow orchestration
Where Human Engineers Remain Essential:
Business logic interpretation and domain expertise
Strategic architecture and decision-making
Complex, ambiguous problem-solving
Ethical oversight and responsible AI governance
Security governance and compliance
Customer experience design and UX innovation
Creative innovation and technology vision
AI cannot fully replicate the contextual understanding and domain expertise that experienced developers bring to enterprise applications. The organizations gaining the greatest competitive advantage are those that combine AI automation with highly skilled engineering teams, not those attempting to replace one with the other.
Why Enterprises Must Act Now
AI-augmented development is already creating a significant competitive divide. Organizations that have adopted AI-driven engineering workflows are reporting measurable, real-world gains:
Faster application delivery and reduced time-to-market
Improved developer productivity and output quality
Reduced operational and infrastructure costs
Enhanced software reliability and fewer production incidents
Shorter release cycles and increased deployment frequency
Greater capacity for innovation and new product development
Meanwhile, enterprises delaying adoption risk falling behind competitors that can deliver digital products faster and more efficiently. Four market forces are driving urgency:
1. Rising Demand for Digital Innovation
Customers expect seamless, intelligent, and highly responsive digital experiences. Enterprises must release features faster while maintaining application reliability.
2. Developer Talent Shortages
Global demand for skilled developers continues to far exceed supply. AI augmentation helps engineering teams scale productivity without dramatically increasing headcount.
3. Increasing Complexity of Enterprise Systems
Modern architectures demand continuous monitoring, integration, and optimization. AI-driven automation helps reduce the operational burden on engineering teams.
4. Pressure to Reduce Costs Without Slowing Innovation
Economic uncertainty is pushing organizations to improve efficiency while sustaining innovation momentum. AI-augmented engineering is one of the most effective levers available.
Key Challenges Enterprises Face in AI-Augmented Development (And How to Overcome Them)
Although the opportunities are compelling, AI adoption introduces critical enterprise challenges that must be addressed proactively.
Governance and Security Risks
AI-generated code may introduce security vulnerabilities, compliance violations, intellectual property concerns, unverified open-source dependencies, and data privacy issues. Without a robust governance framework, enterprises risk deploying insecure or non-compliant applications.
Lack of a Coherent AI Engineering Strategy
Many organizations adopt AI tools in isolation, without a clear integration roadmap. Fragmented experimentation leads to inconsistent outcomes and technical debt rather than meaningful efficiency gains.
Skills Gap in AI Engineering
AI-augmented development requires new engineering capabilities: prompt engineering, AI model governance, human-AI collaboration workflows, AI-assisted DevOps, and AI quality assurance. Building these skills across enterprise teams takes investment and time.
Integration Complexity
AI solutions must integrate seamlessly across CI/CD pipelines, cloud platforms, legacy enterprise applications, security frameworks, and data ecosystems. Poorly integrated AI creates operational silos rather than efficiencies.
5 Strategic Steps Enterprises Must Take to Succeed with AI-Augmented Engineering
Successful AI-augmented development requires a strategic, scalable, and governed approach not ad-hoc tool deployment.
Step 1: Build an Enterprise AI-Augmented Engineering Strategy
Define where AI delivers the highest engineering value, which workflows should remain human-led, governance policies for AI-generated code, and enterprise-wide AI engineering standards aligned to business objectives and security requirements.
Step 2: Modernize Development Pipelines for AI-Native Workflows
Traditional software delivery models are not designed for AI. Enterprises must modernize CI/CD pipelines, DevSecOps processes, cloud-native architectures, automated testing environments, and monitoring and observability frameworks.
Step 3: Upskill Engineering Teams for AI Collaboration
Developers must evolve alongside AI. Invest in AI engineering training, DevOps modernization, cloud-native development practices, AI governance, and responsible AI implementation. The future workforce will consist of engineers who collaborate effectively with intelligent systems.
Step 4: Establish Robust AI Governance Frameworks
Responsible AI adoption requires security validation processes, human review checkpoints, compliance monitoring, ethical AI guidelines, and risk management policies. Strong governance ensures innovation without compromising enterprise security or regulatory standing.
Step 5: Prioritize Human-AI Collaboration Over Full Automation
The most successful enterprises will not fully automate software development. Instead, they will build collaborative ecosystems where AI enhances human productivity and creativity, scaling innovation while preserving strategic oversight.
The Future of AI-Augmented Software Development: What to Expect by 2027
AI-augmented software development is no longer experimental; it is rapidly becoming the standard operating model for forward-looking enterprises.
Over the next two to three years, enterprises can expect:
Autonomous testing environments that self-validate and self-heal
Self-optimizing applications that adapt to usage patterns in real time
AI-driven observability systems that predict and prevent outages
Intelligent deployment orchestration with minimal manual intervention
Predictive software maintenance before failures occur
Hyper-personalized developer environments tailored to individual engineering workflows
The future is not about replacing engineers. It is about transforming software engineering into a more intelligent, strategic, and innovative discipline. Developers will spend less time on repetitive tasks and more time solving the complex, high-value business problems that define competitive advantage.
How Prolifics Helps Enterprises Accelerate AI-Augmented Development
At Prolifics, we help enterprises modernize software engineering practices through AI-powered transformation strategies, cloud-native development, DevOps automation, and intelligent application modernization solutions.
Our expertise includes:
AI-enabled software engineering and development acceleration
We help organizations implement scalable, secure, and responsible AI-augmented development ecosystems that accelerate innovation while maintaining operational resilience.
As AI continues to reshape the future of software development, enterprises must move beyond experimentation and embrace strategic, governed transformation. Prolifics is ready to be your partner on that journey.
Key Takeaways
AI-augmented engineering combines AI tools with human expertise to accelerate software delivery, improve quality, and reduce costs without replacing skilled engineers.
Agentic AI pipelines excel at repetitive tasks and code generation, but human engineers remain essential for business logic, governance, innovation, and security oversight.
Enterprises delaying AI adoption face a growing competitive gap versus organizations already reporting faster delivery cycles and higher developer productivity.
Four forces are driving urgency: rising demand for digital innovation, developer talent shortages, growing system complexity, and pressure to reduce costs.
Successful AI-augmented development requires a governed strategy, not ad-hoc tool deployment, covering pipelines, skills, security, and human-AI collaboration.
AI governance frameworks are non-negotiable: AI-generated code introduces security, compliance, and IP risks that must be actively managed.
The future enterprise dev team will be a human-AI collaborative engineers focused on high-value strategic work, supported by intelligent systems handling repetitive tasks.
Frequently Asked Questions (FAQs)
1. What is AI-augmented engineering?
AI-augmented engineering is the use of AI-powered tools — including coding copilots, agentic pipelines, and automated testing systems — to assist and accelerate software development. It enables enterprise teams to improve productivity and code quality while keeping human engineers in strategic control of decision-making, governance, and innovation.
2. Will AI replace software developers in 2026 or beyond?
No. AI is transforming, not replacing, development teams. While AI automates repetitive tasks such as code generation and testing, human engineers remain essential for business logic, strategic architecture, security governance, customer experience design, and creative innovation. The competitive advantage goes to enterprises that combine both.
3. What are the key benefits of AI-augmented engineering for enterprises?
The primary benefits include faster application delivery, improved developer productivity, reduced operational costs, enhanced software quality, shorter release cycles, accelerated modernization, and increased capacity for innovation, enabling enterprises to stay competitive in a rapidly evolving digital economy.
4. What challenges do enterprises face when implementing AI in software development?
Key challenges include governance and security risks from AI-generated code, lack of a coherent AI engineering strategy, skills gaps in prompt engineering and AI DevOps, and integration complexity with existing enterprise systems. Overcoming these requires a structured strategy, governance policies, and modern pipelines.
5. How can Prolifics help enterprises adopt AI-augmented development?
Prolifics helps enterprises build scalable AI-augmented engineering ecosystems through AI strategy development, DevSecOps transformation, cloud modernization, intelligent automation, application integration, and enterprise AI governance. Our approach accelerates innovation while maintaining security and operational resilience.
6. How does AI-augmented development differ from traditional DevOps?
Traditional DevOps automates deployment and testing pipelines. AI-augmented development goes further using AI to assist in code generation, intelligent debugging, predictive quality assurance, and adaptive workflow optimization. It makes the entire engineering lifecycle more intelligent, not just faster.
Data readiness for AI determines whether enterprise AI initiatives deliver measurable business value – or stall before they scale. As CIOs and CTOs race to deploy generative AI, intelligent automation, and advanced analytics, the most common obstacle is not the technology. It is the data foundation underneath it. Organizations investing in enterprise AI often discover too late that fragmented data, poor governance, legacy systems, and inconsistent data quality prevent AI models from producing reliable outcomes.
AI strategies fail when businesses prioritize models before modernizing their data foundation. Successful AI adoption requires governed, integrated, accessible, and high-quality enterprise data across cloud platforms, applications, and business units. Without data readiness, even advanced AI tools generate inaccurate insights, increase operational risk, and slow digital transformation initiatives.
What Is Data Readiness for AI?
Data readiness is the foundation of a successful AI strategy. Enterprises cannot scale AI initiatives if their data is siloed, inconsistent, poorly governed, or inaccessible across systems. Organizations that prioritize data modernization, cloud integration, governance, and real-time analytics are more likely to achieve measurable ROI from AI, automation, and digital transformation investments.
Data readiness for AI is the process of ensuring enterprise data is accurate, accessible, governed, integrated, and structured for AI and analytics use cases.
It includes data quality management, cloud data modernization, metadata governance, integration across systems, security compliance, and real-time accessibility. AI models depend entirely on the quality and consistency of the data they consume. If enterprise data is fragmented across legacy applications, disconnected business units, and outdated infrastructure, AI systems produce unreliable outputs.
According to IBM, poor data quality costs organizations an average of $12.9 million annually due to operational inefficiencies and decision-making errors.
Data readiness also supports broader digital transformation initiatives such as:
For CTOs and IT leaders, data readiness is not a technical side project. It is the operational layer that determines whether AI can scale securely and effectively across the enterprise. Organizations in healthcare, banking, insurance, and retail face additional complexity because sensitive customer and operational data often exists across hybrid environments, legacy platforms, and third-party systems.
Why Do AI Strategies Fail Without Data Readiness?
Most AI strategies fail because enterprises underestimate the complexity of preparing enterprise data for AI workloads.
A 2024 report from Gartner found that poor data quality remains one of the primary barriers to successful AI adoption across enterprises. AI initiatives often stall after pilot phases because models cannot access trusted, real-time business data consistently across environments.
Common failure points include:
Data silos between departments
Legacy infrastructure limiting integration
Inconsistent governance policies
Duplicate or incomplete records
Limited cloud interoperability
Lack of metadata management
Security and compliance gaps
For example, a retail organization deploying AI-driven demand forecasting may aggregate inventory, e-commerce, and supply chain data from multiple systems. If those systems use inconsistent product identifiers or delayed updates, the AI model generates inaccurate forecasts that directly impact revenue and customer experience.
Similarly, healthcare organizations implementing AI-powered patient engagement platforms require secure integration across EHR systems, insurance databases, scheduling platforms, and clinical applications. Without data standardization and governance, AI recommendations become unreliable and create compliance risks. AI accuracy is not primarily a model problem. In enterprise environments, it is usually a data architecture problem.
How Does Poor Data Quality Impact Enterprise AI Outcomes?
Poor data quality directly reduces AI accuracy, increases operational risk, and weakens business trust in AI systems.
AI models learn patterns from enterprise data. When datasets contain duplication, missing values, outdated information, or inconsistent formatting, models inherit those problems. The result is unreliable analytics, flawed predictions, and automation failures.
According to Forrester, organizations with mature data governance and integration capabilities are significantly more likely to achieve scalable AI outcomes compared to businesses with fragmented data ecosystems.
Key business impacts:
Data Problem
AI Impact
Business Risk
Duplicate customer records
Incorrect predictions
Poor customer experience
Delayed data synchronization
Outdated AI insights
Operational inefficiency
Inconsistent governance
Unreliable outputs
Compliance exposure
Legacy infrastructure
Slow AI deployment
Higher transformation costs
Limited integration
Incomplete analytics
Poor decision-making
Financial services organizations illustrate this challenge clearly. Fraud detection systems rely on real-time transaction data from multiple channels. If transaction streams are delayed or inconsistent across platforms, AI systems may fail to identify fraudulent activity accurately.
The same challenge affects insurance underwriting, healthcare analytics, and retail personalization initiatives. AI systems only perform effectively when enterprise data pipelines are reliable, integrated, and continuously governed.
How Can Enterprises Assess AI Data Readiness?
Enterprises should evaluate AI data readiness across governance, infrastructure, integration, quality, accessibility, and scalability.
Many organizations mistakenly focus only on selecting AI platforms or large language models. The more important question is whether existing enterprise systems can support AI-driven operations consistently across business functions.
A structured AI data readiness assessment typically includes the following areas:
Data Quality Assessment — Evaluate accuracy, completeness, consistency, and duplication across enterprise datasets.
Integration Readiness — Identify disconnected systems, legacy applications, and integration bottlenecks preventing unified data access.
Cloud and Infrastructure Readiness — Assess whether existing infrastructure supports scalable analytics, AI workloads, and real-time processing.
Governance and Compliance — Review security policies, metadata management, lineage tracking, and regulatory compliance frameworks.
Accessibility and Democratization — Ensure business teams can securely access trusted data for analytics and AI use cases.
Operational Scalability — Determine whether data pipelines support continuous AI deployment and enterprise automation initiatives.
Organizations that complete these assessments early avoid expensive AI rework later in transformation programs.
What Steps Improve Data Readiness for AI?
Enterprises improve AI data readiness by modernizing data architecture, standardizing governance, integrating systems, and improving data quality management.
The following framework helps organizations prepare for scalable AI adoption:
Step-by-Step AI Data Readiness Checklist
Audit enterprise data sources — Identify structured and unstructured data across cloud, on-premise, and hybrid environments.
Eliminate data silos — Integrate disconnected systems using APIs, middleware, and enterprise integration platforms.
Improve data quality processes — Standardize validation, cleansing, deduplication, and enrichment practices.
Implement governance frameworks — Establish policies for access control, lineage, metadata, and compliance monitoring.
Modernize cloud data infrastructure — Enable scalable analytics using cloud-native platforms and modern data architectures.
Enable real-time data accessibility — Support AI-driven automation and analytics with low-latency data pipelines.
Align AI use cases with business outcomes — Prioritize initiatives tied to measurable KPIs such as operational efficiency, fraud reduction, or customer experience.
Continuously monitor AI data performance — Track quality metrics, governance compliance, and model reliability over time.
This process creates a stable operational foundation for AI, analytics, and enterprise automation initiatives.
Which Industries Are Most Affected by AI Data Readiness Challenges?
Healthcare, finance, insurance, retail, and public sector organizations face the highest data readiness complexity because they manage large volumes of sensitive, fragmented, and regulated data.
Healthcare
Healthcare providers often operate across disconnected clinical systems, patient portals, insurance databases, and EHR platforms. AI-powered diagnostics and patient engagement require interoperable, secure, and standardized data ecosystems.
Financial Services
Banks and financial institutions rely on real-time transaction processing, fraud detection, and risk analytics. Legacy systems and siloed data environments often slow AI modernization efforts.
Insurance
Insurance providers require integrated customer, claims, underwriting, and policy data to support AI-driven automation and predictive analytics.
Retail
Retailers use AI for personalization, inventory forecasting, and supply chain optimization. Data fragmentation across e-commerce, ERP, POS, and logistics systems can significantly reduce AI effectiveness.
Public Sector
Government agencies face modernization challenges due to aging infrastructure, compliance requirements, and disconnected citizen service platforms.
These industries increasingly invest in cloud migration, enterprise integration, and data governance to support long-term AI transformation strategies.
How Does Modern Data Architecture Support AI Success?
Modern data architecture enables AI scalability by improving integration, governance, accessibility, and real-time processing.
Traditional enterprise architectures were not designed for generative AI, predictive analytics, or intelligent automation workloads. Many organizations still depend on batch processing systems and isolated databases that limit operational agility.
Modern AI-ready architectures typically include:
Legacy Environment
Modern AI-Ready Environment
Siloed applications
Unified enterprise platforms
Batch data processing
Real-time data pipelines
On-premise-only infrastructure
Hybrid and cloud-native systems
Manual governance
Automated governance frameworks
Limited analytics accessibility
Self-service analytics and AI enablement
Point-to-point integrations
API-led system integration
According to IBM, enterprises adopting hybrid cloud and AI-ready architectures improve operational agility while reducing integration complexity.
Modernization also improves:
AI deployment speed
Regulatory compliance
Data observability
Enterprise automation scalability
Cross-functional decision-making
AI transformation is ultimately a data transformation initiative supported by modern architecture and governance practices.
What Does a Real-World AI Data Readiness Scenario Look Like?
Consider a regional healthcare provider implementing AI-powered patient scheduling and predictive care management.
The organization operates across multiple hospitals and outpatient facilities using separate EHR systems, billing platforms, and scheduling tools. Initial AI pilots produced inconsistent recommendations because patient data was duplicated across systems and updated at different intervals.
The provider launched a data modernization initiative that included:
Cloud migration of analytics workloads
Enterprise integration across clinical systems
Data governance implementation
Real-time patient data synchronization
API-led interoperability frameworks
Once the data environment was standardized, the organization improved scheduling accuracy, reduced administrative delays, and enabled more reliable predictive analytics.
This example reflects a common enterprise pattern: AI value increases only after organizations resolve underlying data integration and governance challenges.
These are the types of enterprise modernization initiatives where Prolifics supports organizations through cloud transformation, system integration, AI enablement, and enterprise data modernization strategies.
Key Takeaways
Data readiness for AI is the most critical – and most overlooked – factor in enterprise AI success.
Poor data quality costs organizations an average of $12.9 million annually (IBM) and directly degrades AI accuracy and reliability.
AI strategy failures are usually data architecture problems, not model problems.
Healthcare, finance, insurance, retail, and the public sector face the highest data readiness complexity.
A structured data readiness assessment across quality, governance, integration, cloud infrastructure, and scalability reduces AI rework costs.
Modern AI-ready architectures replace siloed batch systems with real-time, cloud-native, API-led data platforms.
Enterprises that modernize data infrastructure before deploying AI scale faster and achieve measurable ROI sooner.
Frequently Asked Questions
What is data readiness in AI?
Data readiness in AI refers to the process of preparing enterprise data so it can be reliably used for AI, analytics, and automation initiatives. It includes data quality, governance, integration, accessibility, security, and cloud infrastructure modernization to ensure AI systems produce accurate and scalable business outcomes.
Why do enterprise AI projects fail?
Enterprise AI projects often fail because organizations lack integrated, high-quality, and governed data environments. Common issues include legacy infrastructure, disconnected systems, inconsistent governance, and poor data quality, all of which reduce AI reliability and operational scalability.
How do you assess AI data readiness?
Organizations assess AI data readiness by evaluating data quality, governance maturity, infrastructure scalability, system integration, compliance frameworks, and real-time accessibility. Effective assessments identify operational gaps that may limit AI deployment and long-term digital transformation goals.
What industries need AI data readiness the most?
Healthcare, finance, insurance, retail, and public sector organizations face the highest AI data readiness requirements because they manage large volumes of sensitive, regulated, and fragmented enterprise data across multiple systems and environments.
How does cloud modernization improve AI adoption?
Cloud modernization improves AI adoption by enabling scalable storage, real-time processing, system integration, and analytics accessibility. Modern cloud-native architectures also support enterprise automation, governance, and AI deployment across hybrid and distributed business environments.